Serving Large models with VLLM, LLAMA CPP Server, and SGLang
In the rapidly advancing field of artificial intelligence, effectively serving large language models (LLMs) and vision-language models (VLMs) is essential for unlocking their full potential. As these models become more intricate, finding robust and scalable serving solutions is increasingly important. In this guide, we will focus on three prominent projects making strides in this area: VLLM, LLAMA CPP Server, and SGLang.
This part of the series will delve into how to use each of these tools and explore their unique features. We will not be comparing their performance, as each project offers distinct functionalities tailored to different needs. In the second part of the series, we will expand our exploration to additional projects. Understanding these tools' individual strengths will help you choose the most suitable one for your requirements.
VLLM
![]()
VLLM is a high-performance library designed for efficient LLM inference and serving. It excels in throughput and flexibility with features such as state-of-the-art serving capabilities, efficient memory management through PagedAttention, and continuous request batching. Its performance is boosted by CUDA/HIP graph execution and optimized CUDA kernels. VLLM supports various quantization methods and integrates seamlessly with popular HuggingFace models. It also provides high-throughput serving with multiple decoding algorithms, tensor and pipeline parallelism, streaming outputs, and is compatible with both NVIDIA and AMD GPUs. Experimental features include prefix caching and multi-lora support.
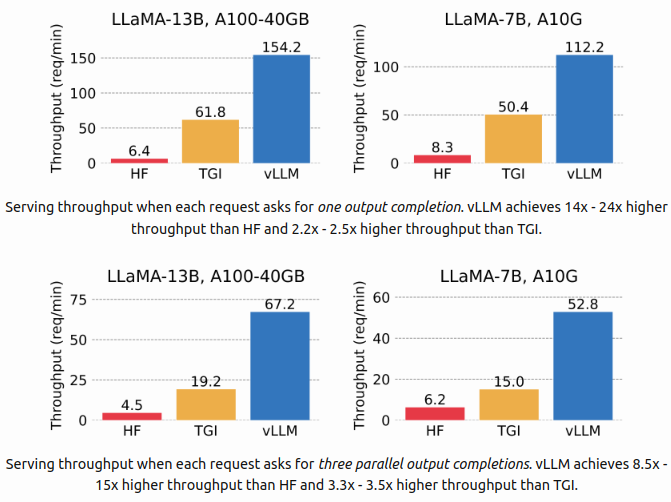
Usage Instructions
To install VLLM, run the following command:
pip install vllm
After installation you can serve your LLMs using the following command:
vllm serve Qwen/Qwen2-1.5B-Instruct --dtype auto --api-key token-abc123
Essential vllm Arguments
--hostHOSTNAME: Server hostname (default: localhost)--portPORT: Server port number (default: 8000)--api-keyKEY: API key for server access (if provided, the server requires this key in the header)--modelMODEL: Name or path of the HuggingFace model to use (e.g., Qwen/Qwen2-1.5B-Instruct)--tokenizerTOKENIZER: Name or path of the tokenizer to use (e.g., Qwen/Qwen2-1.5B-Instruct)--quantizationMETHOD: Quantization method for model weights (e.g., aqlm, awq, fp8, bitsandbytes, None)--dtypeTYPE: Data type for model weights and activations (e.g., auto, half, float16, bfloat16, float32)--deviceDEVICE: Execution device type (e.g., auto, cuda, cpu, tpu)--lora-modulesMODULES: LoRA module configurations (list of name=path pairs)
Deploying with Docker
To deploy VLLM with Docker, run the following command:
docker pull vllm/vllm-openai:v0.5.4
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HUGGING_FACE_HUB_TOKEN=<secret>" \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model Qwen/Qwen2-1.5B-Instruct
To use the endpoint with openai library :
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="token-abc123",
)
completion = client.chat.completions.create(
model="Qwen/Qwen2-1.5B-Instruct",
messages=[
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)
LLaMA.cpp HTTP Server

LLaMA.cpp HTTP Server is a lightweight and fast C/C++ based HTTP server, utilizing httplib, nlohmann::json, and llama.cpp. It offers a set of LLM REST APIs and a simple web interface for interacting with llama.cpp. Key features include support for F16 and quantized models on both GPU and CPU, OpenAI API compatibility, parallel decoding, continuous batching, and monitoring endpoints. It also supports schema-constrained JSON responses and is in development for multimodal capabilities.
Usage Instructions
To install LLaMA.cpp, run the following command:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp && make
After installation, we should download the gguf model (Mistral-7B-Instruct-v0.2-GGUF) from the Hugging Face hub as an example:
cd models && wget https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.2-GGUF/resolve/main/mistral-7b-instruct-v0.2.Q2_K.gguf
To start the server, run the following command:
cd ..
./llama-server -m models/mistral-7b-instruct-v0.2.Q2_K.gguf -c 2048
Essential vllm Arguments
General:
-h, --help, --usage: Print usage and exit--version: Show version and build info-v, --verbose: Print verbose information--verbosity N: Set specific verbosity level (default: 0)--color: Colorize output (default: false)-s, --seed SEED: RNG seed (default: -1, use random seed for < 0)-t, --threads N: Number of threads (default: 8)--ctx-size N: Size of the prompt context (default: 0, 0 = loaded from model)-n, --predict N: Number of tokens to predict (default: -1, -1 = infinity, -2 = until context filled)--prompt PROMPT: Prompt to start generation with (default: '')--interactive: Run in interactive mode (default: false)
Sampling:
--temp N: Temperature (default: 0.8)--top-k N: Top-k sampling (default: 40, 0 = disabled)--top-p N: Top-p sampling (default: 0.9, 1.0 = disabled)--mirostat N: Use Mirostat sampling (default: 0, 0 = disabled, 1 = Mirostat, 2 = Mirostat 2.0)
Model:
-m, --model FNAME: Model path (default: models/$filename)--lora FNAME: Apply LoRA adapter (implies --no-mmap)--control-vector FNAME: Add a control vector--check-tensors: Check model tensor data for invalid values (default: false)
Server:
--host HOST: IP address to listen (default: 127.0.0.1)--port PORT: Port to listen (default: 8080)--timeout N: Server read/write timeout in seconds (default: 600)
Logging:
-ld, --logdir LOGDIR: Path to save YAML logs (no logging if unset)--log-enable: Enable trace logs
Context Hacking:
--rope-scaling {none,linear,yarn}: RoPE frequency scaling method (default: linear)
Parallel:
-np, --parallel N: Number of parallel sequences to decode (default: 1)
Embedding:
--embd-normalize: Normalization for embeddings (default: 2)
Deploying with Docker
To deploy LLaMA.cpp with Docker, run the following command:
docker run -p 8080:8080 -v /path/to/models:/models ghcr.io/ggerganov/llama.cpp:server
-m models/mistral-7b-instruct-v0.2.Q2_K.gguf
-c 512
--host 0.0.0.0
--port 8080
# or, with CUDA:
docker run -p 8080:8080
-v /path/to/models:/models
--gpus all ghcr.io/ggerganov/llama.cpp:server-cuda
-m models/mistral-7b-instruct-v0.2.Q2_K.gguf
-c 512
--host 0.0.0.0
--port 8080
--n-gpu-layers 99
To use the endpoint with openai library :
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8081/v1",
api_key="token-abc123",
)
completion = client.chat.completions.create(
model="Mistral-7B-Instruct-v0.2-GGUF",
messages=[
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)
SGLang
![]()
SGLang is a fast serving framework designed for both LLMs and VLMs, focusing on enhancing interaction speed and control. It features an efficient backend runtime with RadixAttention for prefix caching, jump-forward constrained decoding, and various quantization techniques. SGLang also supports tensor parallelism and advanced kernels for improved performance. The flexible frontend language allows for easy programming of complex LLM applications, including chained generation calls, advanced prompting, and parallelism, as well as integration with multiple modalities and external interactions.
Usage Instructions
To install SGLang, run the following commands:
pip install --upgrade pip
pip install "sglang[all]"
# Install FlashInfer CUDA kernels
pip install flashinfer -i https://flashinfer.ai/whl/cu121/torch2.3/
To start the server, run the following command:
! python -m sglang.launch_server --model-path Qwen/Qwen2-1.5B-Instruct --port 30000
Essential vllm Arguments
Required Options
--model-path MODEL_PATH: Path to model weights (required).
Optional Key Options
--tokenizer-path TOKENIZER_PATH: Path to tokenizer.--host HOST: Server host (default could belocalhost).--port PORT: Server port (default could be8000or another common port).--tokenizer-mode {auto,slow}: Default is likelyauto.--load-format {auto,pt,safetensors,npcache,dummy}: Default is likelyauto.--dtype {auto,half,float16,bfloat16,float,float32}: Default could beauto.--context-length CONTEXT_LENGTH: Default isNone, uses model's config value.
Performance and Resource Options
--mem-fraction-static MEM_FRACTION_STATIC: Fraction of memory for static allocation.--max-prefill-tokens MAX_PREFILL_TOKENS: Maximum tokens in prefill batch.--max-running-requests MAX_RUNNING_REQUESTS: Max running requests.--max-num-reqs MAX_NUM_REQS: Max requests in memory pool.--max-total-tokens MAX_TOTAL_TOKENS: Max tokens in memory pool.
Scheduling and Parallelism
--schedule-policy {lpm,random,fcfs,dfs-weight}: Scheduling policy, default could befcfs(First Come First Served).--tp-size TP_SIZE: Tensor parallelism size.--dp-size DP_SIZE: Data parallelism size.
Logging and Debugging
--log-level LOG_LEVEL: Logging level.--log-requests: Log requests.--show-time-cost: Show time cost of custom marks.
Advanced Options
--quantization {awq,fp8,gptq,marlin,gptq_marlin,awq_marlin,squeezellm,bitsandbytes}: Quantization method.--load-balance-method {round_robin,shortest_queue}: Load balancing strategy.
Experimental or Optional Features
--enable-torch-compile: Experimental optimization feature.--disable-disk-cache: Disable disk cache.
Deploying with Docker
To deploy SGLang with Docker, run the following command:
docker pull lmsysorg/sglang:v0.2.10-cu124
docker run --gpus all \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HF_TOKEN=<secret>" \
--ipc=host \
lmsysorg/sglang:latest \
python3 -m sglang.launch_server --model-path Qwen/Qwen2-1.5B-Instruct --host 0.0.0.0 --port 30000
To use the endpoint with openai library :
import openai
client = openai.Client(
base_url="http://127.0.0.1:30000/v1", api_key="EMPTY")
# Text completion
response = client.completions.create(
model="default",
prompt="The capital of France is",
temperature=0,
max_tokens=32,
)
print(response)