Building a Simple Question-Answering Pipeline from Scratch
Ever wondered how AI systems can answer your questions based on a vast collection of documents? The secret sauce is often a technique called Retrieval Augmented Generation (RAG). While powerful RAG frameworks like LangChain and LlamaIndex simplify the process, understanding the underlying mechanisms is crucial.
This blog post will guide you through building a simple, yet functional, RAG pipeline from the ground up, We'll break down each component, from loading PDFs to generating answers, giving you a solid foundation in how RAG works at a medium code level.
This hands-on approach will demystify the core concepts of:
- Document Loading and Processing: Extracting text from PDFs and splitting it into manageable chunks.
- Embedding Generation and Storage: Transforming text into numerical representations for efficient similarity search.
- Similarity Search: Finding relevant chunks based on your questions.
- Reranking: Refining search results for higher accuracy.
- Answer Generation: Using a small and powerful language model to synthesize answers from the retrieved information.
By the end, you'll have a working RAG pipeline, providing a clear understanding of the fundamental principles. This is the perfect starting point for anyone looking to delve into the fascinating world of question-answering systems and build their own custom solutions!
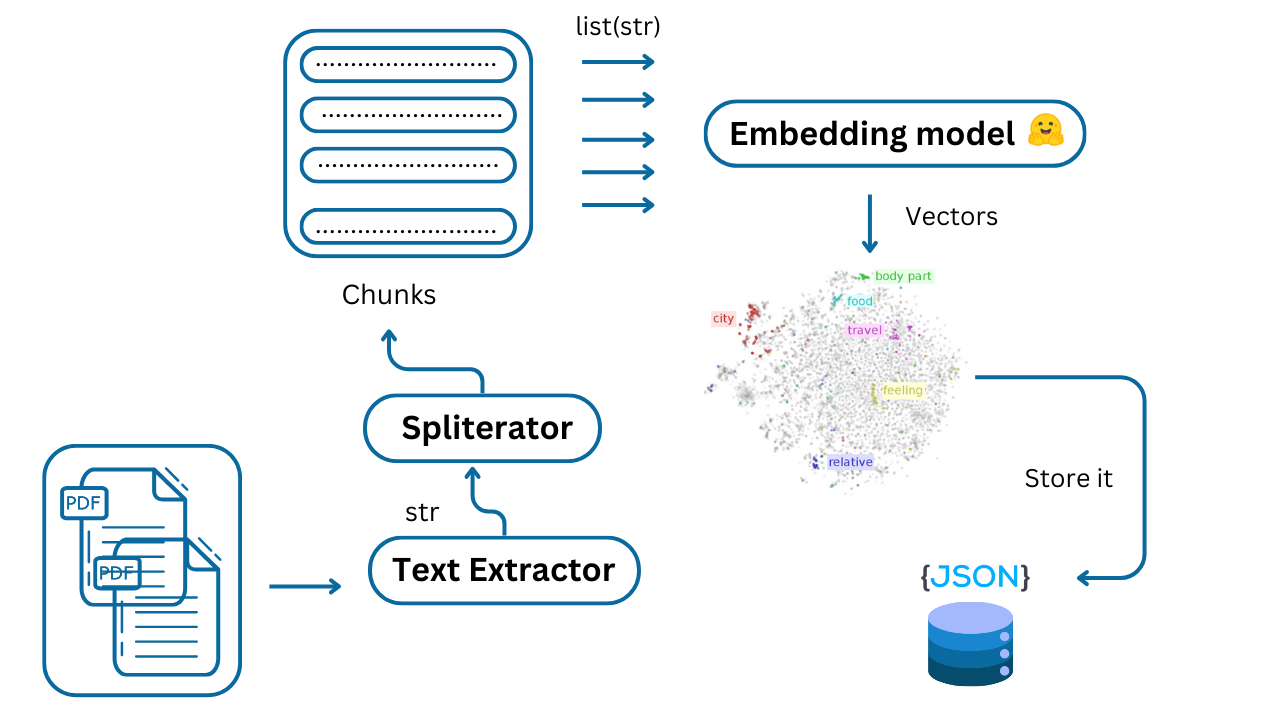
1. Installing Dependencies
pip install sentence-transformers PyPDF2
We need two essential python libraries:
sentence-transformers: This library provides pre-trained models for generating sentence embeddings, which are numerical representations of text that capture semantic meaning. These embeddings are important for similarity search task.PyPDF2: This library is used for reading and extracting text from PDF files.
2. Extracting Text from PDFs
We define here a function get_pdf_text that iterates through all PDF files in the specified data_folder and extracts the text from each page using PyPDF2.
# Loop through files in the data folder
from PyPDF2 import PdfReader
import os
data_folder = 'data'
def get_pdf_text(pdf_path):
"""
Extracts text from a PDF file.
:param pdf_path: The path to the PDF file.
:return: The extracted text from the PDF.
"""
total_text = ''
for filename in os.listdir(pdf_path):
if filename.lower().endswith('.pdf'):
pdf_path = os.path.join('data', filename)
with open(pdf_path, 'rb') as file:
reader = PdfReader(file)
for page in reader.pages:
total_text += page.extract_text() or ''
return total_text
total_text = get_pdf_text(data_folder)
The extracted text is concatenated into a single string
total_text.
3. Splitting Text into Chunks
The regex_splitter function splits the extracted text into smaller chunks of a specified size (chunk_size) with optional overlap (overlap).
import re
def regex_splitter(text: str, chunk_size: int, overlap: int):
"""
split the input text into chunks of the specified size with optional overlap.
:param text: The input text to be split.
:param chunk_size: The size of each chunk.
:param overlap: The amount of overlap between consecutive chunks.
:return: A list of text chunks.
"""
# Regular expression to match sentence endings (period, question mark, etc.)
sentence_endings = re.compile(r"(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=\.|\?)\s")
# Split the text into sentences based on sentence endings
sentences = sentence_endings.split(text)
# Initialize variables for chunking
chunks = []
current_chunk = ""
# Iterate through each sentence and create chunks
for sentence in sentences:
# If adding the current sentence to the current chunk doesn't exceed the chunk size, add it
if len(current_chunk) + len(sentence) + 1 <= chunk_size:
current_chunk += " " + sentence
# Otherwise, add the current chunk to the list and reset it
else:
chunks.append(current_chunk.strip())
current_chunk = sentence
# Add the last chunk if it exists
if current_chunk:
chunks.append(current_chunk.strip())
# If overlap is specified, create overlapping chunks
if overlap > 0:
overlapping_chunks = []
for i in range(len(chunks)):
# Calculate the start and end indices for the current overlapping chunk
start = max(0, i * chunk_size - i * overlap)
end = start + chunk_size
# Add the overlapping chunk to the list
overlapping_chunks.append(text[start:end].strip())
return overlapping_chunks
else:
return chunks
chunks = regex_splitter(text=total_text, chunk_size=1024, overlap=50)
Chunking and Overlap: Breaking down large documents into smaller chunks is crucial for efficiency. The
regex_splitterfunction intelligently uses regular expressions to split the text based on sentence boundaries. Theoverlapparameter ensures that context is preserved across chunks, preventing the loss of potentially relevant information at the boundaries.
4. Loading the Embedding Model
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
emb_model = SentenceTransformer('Alibaba-NLP/gte-base-en-v1.5', trust_remote_code=True)
This code loads a pre-trained sentence embedding model from Hugging Face's Model Hub. The trust_remote_code=True argument is necessary because this particular model requires compiling custom code.
5. Storing Embeddings Function:
The store_embeddings function takes a list of sentences, generates embeddings for each sentence using the loaded embedding model, and stores them in a JSON file.
import json
import numpy as np
def store_embeddings(sentences:list[str], emb_model:SentenceTransformer, filename:str):
"""
Stores embeddings for the given sentences in a JSON file.
:param sentences: A list of sentences.
:param emb_model: The embedding model.
:param filename: The path to the JSON file.
"""
if not sentences:
print("Warning: The sentences list is empty. No embeddings will be stored.")
return
try:
# Convert sentences to embeddings
embeddings = emb_model.encode(sentences)
except Exception as e:
print(f"Error during encoding: {e}")
return
# Create a dictionary with sentences as keys and embeddings as values
embeddings_dict = {}
for i in range(len(sentences)):
try:
embeddings_dict[sentences[i]] = embeddings[i].tolist()
except Exception as e:
print(f"Error processing sentence '{sentences[i]}': {e}")
try:
# Save the dictionary to a JSON file
with open(filename, 'w') as f:
json.dump(embeddings_dict, f)
except IOError as e:
print(f"Error saving embeddings to file {filename}: {e}")
except Exception as e:
print(f"Unexpected error: {e}")
store_embeddings(chunks, emb_model, 'embeddings.json')
This allows us to pre-compute and store embeddings, saving time during query processing.
6. Loading Embeddings
The load_embeddings function loads the pre-computed embeddings from the JSON file.
from scipy.spatial.distance import cosine, euclidean, cityblock
def load_embeddings(filename:str):
"""
Loads embeddings from a JSON file.
:param filename: The path to the JSON file.
:return: A dictionary with sentences as keys and embeddings as values.
"""
with open(filename, 'r') as f:
embeddings_dict = json.load(f)
embeddings_dict = {k: np.array(v) for k, v in embeddings_dict.items()}
return embeddings_dict
stored_embeddings = load_embeddings('embeddings.json')
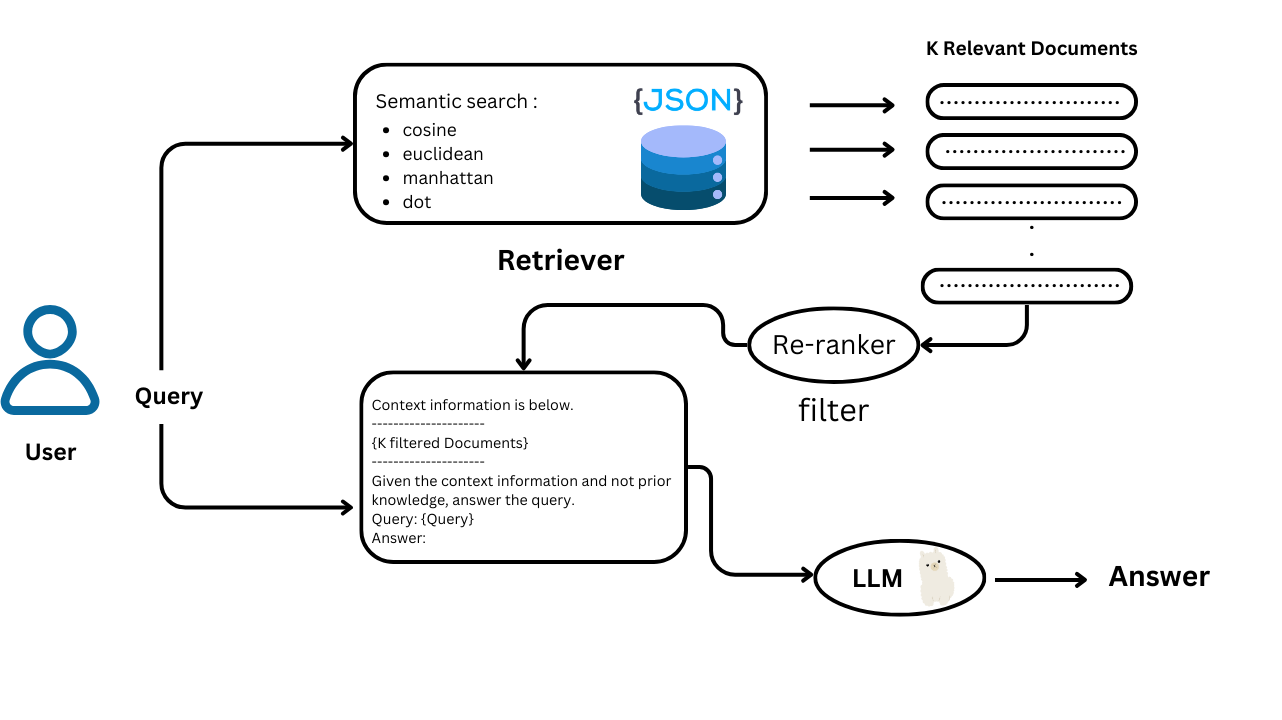
7. Finding Similar Sentences Functions
The find_similar_sentences function takes an input sentence, generates its embedding, and compares it to the stored embeddings using a specified similarity metric (e.g., cosine similarity).
def find_similar_sentences(input_sentence:str, emb_model:SentenceTransformer, stored_embeddings:dict[str, np.array], metric:str='cosine', threshold:float=0.8, top_k:int=5):
input_embedding = emb_model.encode([input_sentence])[0]
# Define a function for each metric
def calculate_similarity(embedding1, embedding2, metric):
if metric == 'cosine':
return 1 - cosine(embedding1, embedding2) # Cosine similarity
elif metric == 'euclidean':
return 1 - (euclidean(embedding1, embedding2) / np.sqrt(len(embedding1))) # Euclidean similarity
elif metric == 'manhattan':
return 1 - (cityblock(embedding1, embedding2) / np.sqrt(len(embedding1))) # Manhattan similarity
elif metric == 'dot':
return np.dot(embedding1, embedding2) / (np.linalg.norm(embedding1) * np.linalg.norm(embedding2)) # Dot product
else:
raise ValueError(f"Unknown metric: {metric}")
similarities = {}
try:
for sentence, embedding in stored_embeddings.items():
try:
similarities[sentence] = calculate_similarity(input_embedding, embedding, metric)
except Exception as e:
print(f"Error calculating similarity for sentence '{sentence}': {e}")
similarities[sentence] = -1 # Assign a default low value in case of an error
except Exception as e:
print(f"Error calculating similarities: {e}")
return []
# Filter sentences based on similarity threshold
try:
filtered_similarities = {sentence: similarity for sentence, similarity in similarities.items() if similarity >= threshold}
except Exception as e:
print(f"Error filtering similarities: {e}")
return []
# Sort sentences by similarity score in descending order
try:
sorted_sentences = sorted(filtered_similarities.items(), key=lambda item: item[1], reverse=True)
except Exception as e:
print(f"Error sorting sentences: {e}")
return []
# Select the top k sentences
try:
top_sentences = [sentence for sentence, _ in sorted_sentences[:top_k]]
except Exception as e:
print(f"Error selecting top {top_k} sentences: {e}")
return []
return top_sentences
It returns the top k most similar sentences based on a similarity threshold.
Sentence Embeddings: The core of any similarity search is the ability to represent textual information in a numerical format that captures semantic meaning. This is where sentence embeddings come in. The code uses the
sentence-transformerslibrary to generate these embeddings. Think of them as vectors representing the meaning of each sentence. Similar sentences will have vectors that are closer together in this vector space.
cosine, Euclidean, Manhattan, and dot product : Each of these metrics provides a different way to measure the similarity between two vectors (in this case, sentence embeddings).
1. Cosine Similarity:
- Concept: Measures the cosine of the angle between two vectors.
- Interpretation:
- 1: Vectors are identical (pointing in the same direction).
- 0: Vectors are orthogonal (completely dissimilar).
- -1: Vectors are diametrically opposed.
- Advantages:
- Robust to differences in vector magnitudes (length). Focuses on the orientation.
- Widely used in text analysis and information retrieval.
- Formula:
cosine_similarity(A, B) = (A . B) / (||A|| * ||B||)A . B: Dot product of vectors A and B.||A||: Magnitude (length) of vector A.||B||: Magnitude (length) of vector B.
2. Euclidean Distance:
- Concept: Measures the straight-line distance between two points in Euclidean space.
- Interpretation:
- 0: Vectors are identical (same point in space).
- Larger values: Indicate greater dissimilarity.
- Advantages:
- Intuitive and commonly used distance metric.
- Disadvantages:
- Sensitive to differences in vector magnitudes.
- Formula:
euclidean_distance(A, B) = sqrt(sum((A_i - B_i)^2))A_i: The i-th element of vector A.B_i: The i-th element of vector B.
3. Manhattan Distance (Cityblock Distance):
- Concept: Measures the distance between two points by summing the absolute differences of their coordinates. Imagine navigating a city grid - you can only move along streets (horizontally and vertically).
- Interpretation:
- 0: Vectors are identical.
- Larger values: Indicate greater dissimilarity.
- Advantages:
- Less sensitive to outliers compared to Euclidean distance.
- Disadvantages:
- May not be as accurate as Euclidean distance for capturing true geometric distance.
- Formula:
manhattan_distance(A, B) = sum(|A_i - B_i|)|A_i - B_i|: Absolute difference between the i-th elements of vectors A and B.
4. Dot Product:
- Concept: Measures the projection of one vector onto another.
- Interpretation:
- Large positive value: Vectors are similar and point in the same general direction.
- Large negative value: Vectors are dissimilar and point in opposite directions.
- 0: Vectors are orthogonal (no projection).
- Advantages:
- Computationally efficient.
- Disadvantages:
- Sensitive to vector magnitudes. Doesn't inherently represent a normalized similarity score like cosine similarity.
- Formula:
dot_product(A, B) = sum(A_i * B_i)
8. Loading the Reranker Model
We load here a pre-trained bge-reranker-v2-m3 reranker model, which is used to refine the initial retrieval results.
import torch
from torch.nn.functional import softmax
from transformers import AutoModelForSequenceClassification, AutoTokenizer
reranker_model_name = 'BAAI/bge-reranker-v2-m3'
reranker_tokenizer = AutoTokenizer.from_pretrained(reranker_model_name)
reranker_model = AutoModelForSequenceClassification.from_pretrained(reranker_model_name)
reranker_model.eval()
The reranker helps to identify the most relevant passages for answering the user's query.
9. Reranking Function
The initial retrieval based on similarity might not always be perfect. That's where the reranker model comes in. It acts as a second layer of filtering, using a more sophisticated model to assess the relevance of each retrieved passage to the user's query. This helps to improve the quality of the final answer.
def reranker(pairs:list[list[str]], threshold:float):
"""
Reranks pairs based on a model's scores and a given probability threshold.
Parameters:
- pairs (list of list of str): List of [query, candidate] pairs.
- threshold (float): Probability threshold for filtering the pairs.
Returns:
- filtered_answers (list of str): List of answers from the pairs that pass the threshold.
- filtered_probabilities (torch.Tensor): Probabilities corresponding to the filtered answers.
"""
if not pairs:
print("Warning: The input pairs list is empty.")
return [], []
try:
with torch.no_grad():
# Tokenize the input pairs
inputs = reranker_tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
except Exception as e:
print(f"Error during tokenization: {e}")
return [], []
try:
# Get the scores from the model
scores = reranker_model(**inputs, return_dict=True).logits.view(-1).float()
except Exception as e:
print(f"Error getting scores from the model: {e}")
return [], []
try:
# Apply softmax to get probabilities
probabilities = softmax(scores, dim=0)
except Exception as e:
print(f"Error applying softmax: {e}")
return [], []
try:
# Filter pairs based on the threshold
high_prob_indices = probabilities > threshold
filtered_probabilities = probabilities[high_prob_indices]
# Extract only the answers and their corresponding scores
filtered_answers = [pairs[i][1] for i in range(len(pairs)) if high_prob_indices[i]]
except Exception as e:
print(f"Error during filtering or extraction: {e}")
return [], []
return filtered_answers, filtered_probabilities
The reranker function takes a list of pairs (each pair contains a query and a candidate answer) and uses the reranker model to score each pair. It filters out pairs that fall below a specified threshold.
10. Loading the Language Model (LLM)
Here we loads a large language model (LLM) called Qwen2-1.5B-Instruct. This model will be used to generate the final answer based on the retrieved and reranked passages.
from transformers import AutoModelForCausalLM, AutoTokenizer , TextStreamer
model_name = "Qwen/Qwen2-1.5B-Instruct"
device = "cuda" if torch.cuda.is_available() else "cpu"
# Now you do not need to add "trust_remote_code=True"
model = AutoModelForCausalLM.from_pretrained(model_name , device_map=device)
tokenizer = AutoTokenizer.from_pretrained(model_name)
11. Custom Text Streamer (optional)
This class defines a custom text streamer that allows you to print the output tokens as they are generated by the LLM. This is useful for monitoring the generation process.
class CustomTextStreamer(TextStreamer):
"""
A custom streamer that prints the output tokens as they are generated.
"""
def __init__(self, tokenizer, skip_prompt=False, skip_special_tokens=False):
super().__init__(tokenizer, skip_prompt=skip_prompt, skip_special_tokens=skip_special_tokens)
def __call__(self, output_ids):
# Decode and print the output tokens as they are generated
text = self.tokenizer.decode(output_ids, skip_special_tokens=self.skip_special_tokens)
print(text, end='', flush=True)
streamer = CustomTextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
12. Pipeline Function
The generate function takes a list of messages and uses the loaded tokenizer and LLM to generate text. It prepares the input for the LLM and handles the generation process.
def generate(messages:list[dict[str,str]]):
"""
Processes messages using a tokenizer and model to generate text.
Parameters:
- messages (list of str): List of messages to process.
- tokenizer (transformers.PreTrainedTokenizer): Tokenizer for encoding and decoding.
- model (transformers.PreTrainedModel): Model for generating text.
- device (torch.device): Device to run the model on (CPU or GPU).
Returns:
- str: Generated text from the model.
"""
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
streamer=streamer,
)
13. Main Run Function
The run function orchestrates the entire RAG pipeline:
- It calls
find_similar_sentencesto retrieve relevant passages. - It creates pairs of (query, passage) for the reranker.
- It calls
rerankerto refine the retrieved passages. - It constructs the final context for the LLM.
- It calls
pipeto generate the answer using the LLM.
reranker_threshold = 0.6
similarity_threshold = 0.3
top_k = 10
metric = 'cosine' # you can choose cosine, Euclidean, Manhattan, and dot product
def run(prompt : str) :
"""
Executes the full pipeline: similarity search, reranking, and text generation.
Parameters:
- prompt (str): The input query for which the response is generated.
"""
# Simularity search
similar_sentences = find_similar_sentences(prompt, emb_model, stored_embeddings, metric=metric, threshold=similarity_threshold , top_k=top_k)
# Create Pairs
pairs = [[prompt, sentence] for sentence in similar_sentences]
# Reranker
filtered_answers, _ = reranker(pairs, reranker_threshold)
# Generator
context = "\n".join(filtered_answers)
content = f"""
Context information is below.\n
---------------------\n
{context}\n"
---------------------\n
Given the context information and not prior knowledge,
answer the query.\n
Query: {prompt}\n
Answer:
"""
print("Content : \n" , content)
messages = [
{"role": "system", "content": "You are a helpful assistant."} ,
{"role": "user", "content": content},
]
# Run the text generator
generate(messages)
14. Running the Pipeline
Finally, we can call the run function with a sample query, initiating the entire RAG pipeline and getting answers from our Pdfs.
text = "Ask about you Documents"
run(text)
While this simple RAG pipeline might not be perfect, it provides a valuable foundation for understanding the core principles behind retrieval augmented generation. By building each component from scratch, we've gained a deeper appreciation for how document processing, embedding generation, similarity search, reranking, and language model integration work together to answer questions based on a given knowledge base. This is a solid starting point for further exploration and customization. As you delve deeper into the world of RAG, you can explore more advanced techniques, experiment with different models, and refine the pipeline to achieve even greater accuracy and performance. So, keep learning, keep building, good luck and Happy prompting..