A Step-by-Step Guide to Improving Language Model Accuracy with Corrective Retrieval-Augmented Generation
Large Language Models (LLMs) are great at generating human-like text, but they sometimes struggle with factual accuracy. This can lead to hallucinations, where the model confidently generates incorrect information. One way to address this is through Retrieval-Augmented Generation (RAG), which enhances the LLM’s input with relevant knowledge retrieved from external sources like Wikipedia.
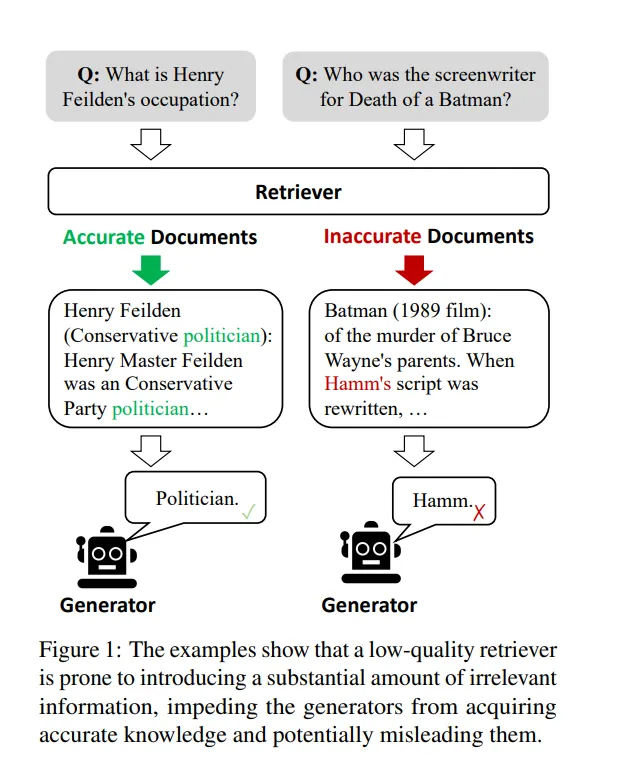
However, RAG can be unreliable if the retriever fails to provide accurate information. This is where Corrective Retrieval Augmented Generation (CRAG) steps in. CRAG aims to improve the robustness of RAG by introducing a mechanism for self-correction.
How CRAG Works
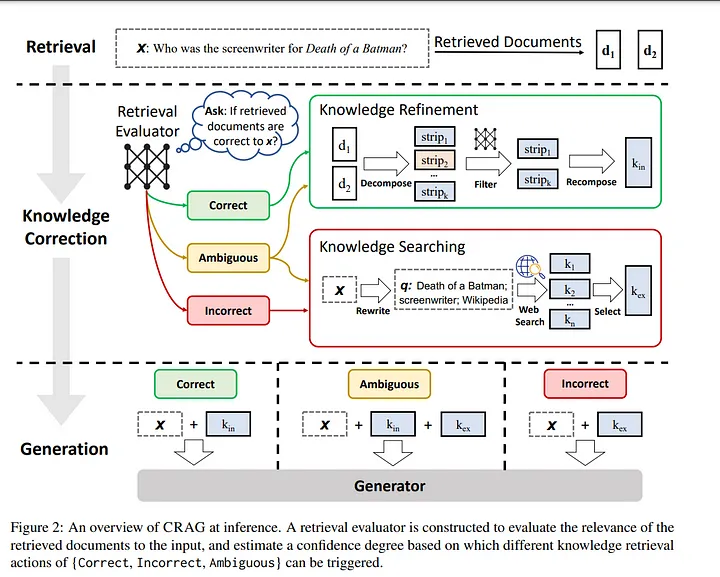
CRAG employs a lightweight retrieval evaluator, a model specifically trained to assess the quality of retrieved documents. This evaluator assigns a confidence score to each retrieved document, which determines how the model should proceed:
- Correct: If the confidence score is high enough, the model assumes the retrieved document is relevant and accurate. However, it further refines the document using a knowledge decomposition, filtering, and recomposition algorithm to extract the most relevant information.
- Incorrect: If the confidence score is too low, the model discards the retrieved documents and resorts to large-scale web searches to find more relevant information. This allows CRAG to tap into the vast resources of the internet for knowledge correction.
- Ambiguous: In cases where the evaluator is uncertain, CRAG combines both the refined retrieved document and the web search results to create a balanced knowledge source for the generator.
CRAG’s Advantages:
- Plug-and-Play: CRAG can be easily integrated with existing RAG-based approaches.
- Improved Accuracy: Experiments on diverse datasets demonstrate that CRAG significantly improves the performance of both standard RAG and the advanced Self-RAG.
- Generalizability: CRAG shows consistent effectiveness across various generation tasks, from short-form entity generation to long-form biographies and closed-set question answering.
Understanding the Importance of Each Component
Ablation studies (where specific parts of CRAG are removed) confirm the crucial role of each component:
- Retrieval evaluator: CRAG’s lightweight retrieval evaluator consistently outperforms even a powerful model like ChatGPT in accurately identifying relevant documents.
- Triggered Actions: Each of CRAG’s three actions (Correct, Incorrect, Ambiguous) contributes to the system’s overall robustness. Removing any action results in a performance drop.
- Knowledge Refinement and Utilization: Removing any of the knowledge refinement steps (document refinement, search query rewriting, external knowledge selection) leads to a significant decrease in accuracy. This highlights the importance of effectively utilizing the retrieved knowledge.
CRAG’s Resilience to Retrieval Errors:
CRAG’s performance remains stable even when the retrieval quality declines. This contrasts with traditional RAG, whose performance drops significantly as the retriever’s accuracy diminishes. CRAG’s ability to handle unreliable retrieval results makes it a more robust solution.
CRAG: A Promising Future for Retrieval-Augmented Generation
CRAG offers a promising approach to enhance the reliability of retrieval-augmented generation. By providing a mechanism for self-correction and robustly managing retrieved knowledge, CRAG helps ensure that LLMs can generate more accurate and trustworthy outputs.
🦜🕸️LangGraph
LangGraph is a library for building stateful, multi-actor applications with LLMs, used to create agent and multi-agent workflows. Compared to other LLM frameworks, it offers these core benefits: cycles, controllability, and persistence. LangGraph allows you to define flows that involve cycles, essential for most agentic architectures, differentiating it from DAG-based solutions. As a very low-level framework, it provides fine-grained control over both the flow and state of your application, crucial for creating reliable agents. Additionally, LangGraph includes built-in persistence, enabling advanced human-in-the-loop and memory features.
Code Time
Setting Up the Environment
To build the CRAG system, you first need to set up your environment and configure the API key for the Cohere models. The following code block initializes the environment variable for the Cohere API key, which you’ll use for accessing the LLM and embedding models.
import os
os.environ["CO_API_KEY"] = ""
We need to install several essential Python packages.
! pip install langchain_core langchain langchain_cohere langchain-community langchain-chroma duckduckgo-search pypdf langgraph langchainhub
With the necessary packages installed, it’s time to set up the large language model (LLM), embedding model, and document retriever that will be central to your system.
# import
from langchain_chroma import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFDirectoryLoader
from langchain_cohere import CohereEmbeddings
from langchain_community.llms import Cohere
llm = Cohere(model="command-r-plus", max_tokens=1024, temperature=0.2)
def Retriever(folder_path,chunk_size=1200, chunk_overlap=200):
# Load documents from the specified folder
loader = PyPDFDirectoryLoader(folder_path)
documents = loader.load()
# Split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size , chunk_overlap=chunk_overlap)
chunks = text_splitter.split_documents(documents)
embeddings = CohereEmbeddings(model="embed-english-light-v3.0")
# Create a Chroma vector store from the document chunks and embeddings
db = Chroma.from_documents(chunks, embeddings)
return db.as_retriever()
# Initialize the Retriever with the path to your PDF data source
retriever = Retriever(file_name="your_data_source_folder",chunk_size=1200, chunk_overlap=200)
Now that you have set up the Retriever function and created an instance of the retriever, it's important to test it to ensure that it retrieves relevant documents based on a given query.
Below is a simple test for the Retriever to check if it can handle a sample query and retrieve relevant documents:
# Test the Retriever with a sample query
query = "What is Self RAG?"
result = retriever.invoke(query)
# Print the retrieved documents
print(result)
Building the Graph State
import json
import operator
from typing import Annotated, Sequence, TypedDict
from langchain import hub
from langchain_core.output_parsers import JsonOutputParser
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_community.tools import DuckDuckGoSearchRun
from typing import Annotated, Dict, TypedDict
from langchain_core.messages import BaseMessage
To implement CRAG, you will need to set up a state machine to manage the transitions between different stages of the retrieval and generation process. This state machine will be represented as a StateGraph, where nodes represent the LLM and various functions, and edges specify transitions between these functions based on the state of the retrieval process.
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
keys: A dictionary where each key is a string.
"""
keys: Dict[str, any]
Defining the Nodes
In Our system, each node represents a distinct function or process step. For each node, you’ll define a function that performs a specific task and updates the state of the graph accordingly.
Here, we’ll start by defining the retrieve node function :
This function retrieves documents that are relevant to the user’s question. It takes the current state of the graph, extracts the question, and uses the retriever to find pertinent documents. The retrieved documents are then added to the state, ready for further processing.
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
state_dict = state["keys"]
question = state_dict["question"]
documents = retriever.get_relevant_documents(question)
return {"keys": {"documents": documents, "question": question}}
The generate function uses the LLM to generate an answer based on the refined and relevant documents retrieved in the previous steps. It constructs a comprehensive response to the user's query.
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains generation
"""
print("---GENERATE---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
generation = rag_chain.invoke({"context": documents, "question": question})
return {
"keys": {"documents": documents, "question": question, "generation": generation}
}
We define the grade_documents function. This function evaluates the relevance of the retrieved documents to the user's question. It assigns a binary score ('yes' or 'no') to each document to filter out irrelevant ones, ensuring only pertinent information is used in the subsequent steps.
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with relevant documents
"""
print("---CHECK RELEVANCE---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
prompt = PromptTemplate(
template="""You are a grader assessing relevance of a retrieved document to a user question. \n
Here is the retrieved document: \n\n {context} \n\n
Here is the user question: {question} \n
If the document contains keywords related to the user question, grade it as relevant. \n
It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question. \n
Provide the binary score as a JSON with a single key 'score' and no preamble or explanation.""",
input_variables=["question", "context"],
)
chain = prompt | llm | JsonOutputParser()
# Score
filtered_docs = []
relevant_count = 0
for d in documents:
score = chain.invoke(
{
"question": question,
"context": d.page_content,
}
)
grade = score["score"]
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
relevant_count += 1
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
relevance_ratio = relevant_count / len(documents)
search = "Yes" if relevance_ratio < 0.6 else "No"
return {
"keys": {
"documents": filtered_docs,
"question": question,
"run_web_search": search,
}
}
Now, let’s define the transform_query function. This function takes the current question and rephrases it to produce a better-optimized query for retrieval. The improved question helps in fetching more relevant documents from the web or database.
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("---TRANSFORM QUERY---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
# Create a prompt template with format instructions and the query
prompt = PromptTemplate(
template="""You are generating questions that is well optimized for retrieval. \n
Look at the input and try to reason about the underlying sematic intent / meaning. \n
Here is the initial question:
\n ------- \n
{question}
\n ------- \n
Provide an improved question without any premable, only respond with the updated question: """,
input_variables=["question"],
)
# Prompt
chain = prompt | llm | StrOutputParser()
better_question = chain.invoke({"question": question})
return {
"keys": {"documents": documents, "question": better_question}
}
In this step, we define the web_search function. This function performs a web search using the DuckDuckGo search engine based on the re-phrased question generated in the previous step. The search results are then appended to the existing list of documents. This allows our system to gather additional relevant information from the web, enhancing the overall knowledge base.
def web_search(state):
"""
Web search based on the re-phrased question using Tavily API.
Args:
state (dict): The current graph state
Returns:
state (dict): Web results appended to documents.
"""
print("---WEB SEARCH---")
state_dict = state["keys"]
question = state_dict["question"]
documents = state_dict["documents"]
duckduckgo_search = DuckDuckGoSearchRun()
docs = duckduckgo_search.invoke({"query": question})
web_results = "\n".join(docs)
web_results = Document(page_content=web_results)
documents.append(web_results)
return {"keys": {"documents": documents,"question": question}}
Next, we define the decide_to_generate function. This function determines the next action based on the relevance of the retrieved documents. If the documents are not relevant, it suggests transforming the query and performing a web search. If the documents are relevant, it proceeds to generate an answer.
def decide_to_generate(state):
"""
Determines whether to generate an answer or re-generate a question for web search.
Args:
state (dict): The current state of the agent, including all keys.
Returns:
str: Next node to call
"""
print("---DECIDE TO GENERATE---")
state_dict = state["keys"]
question = state_dict["question"]
filtered_documents = state_dict["documents"]
search = state_dict["run_web_search"]
if search == "Yes":
# All documents have been filtered check_relevance
# We will re-generate a new query
print("---DECISION: TRANSFORM QUERY and RUN WEB SEARCH---")
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
Now, let’s define the workflow for our CRAG system using the StateGraph object from the langgraph library. This workflow outlines how the system transitions between various states, such as retrieving documents, grading their relevance, generating answers, transforming queries, and performing web searches.
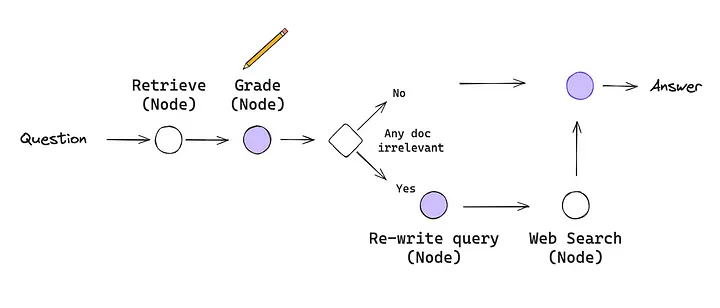
Build the graph
First, we import the necessary modules and initialize the StateGraph with our graph state. Then, we add nodes for each function and define the entry point and edges for the workflow. Conditional edges are used to decide whether to generate an answer or transform the query for a web search based on the relevance of the retrieved documents.
Finally, we compile the workflow into an executable application.
import pprint
from langgraph.graph import END, StateGraph
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generate
workflow.add_node("transform_query", transform_query) # transform_query
workflow.add_node("web_search", web_search) # web search
# Build graph
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "web_search")
workflow.add_edge("web_search", "generate")
workflow.add_edge("generate", END)
# Compile
app = workflow.compile()
To execute the CRAG workflow, we need to provide an initial input, which in this case is a question we want the system to answer.
The inputs dictionary contains the initial state with the question key. We then stream the output from the compiled application and print the state at each node along the way. Finally, we print the generated answer from the workflow.
# Run
inputs = {
"keys": {
"question": "what is all about ?"}
}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint.pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint.pprint("\n---\n")
# Final generation
pprint.pprint(value['keys']['generation'])
Output Example :
---RETRIEVE---
"Node 'retrieve':"
'\n---\n'
---CHECK RELEVANCE---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---DECIDE TO GENERATE---
---DECISION: GENERATE---
"Node 'grade_documents':"
'\n---\n'
---GENERATE---
"Node 'generate':"
'\n---\n'
('SELF-RAG is a framework that enhances the quality and factual accuracy of '
'language models by combining retrieval and self-reflection. It trains a '
'single LM to retrieve relevant passages on demand and reflect on its output '
'to improve overall quality. This approach addresses the limitations of '
'conventional Retrieval-Augmented Generation (RAG).')
Explanation of this Output Example
- RETRIEVE: Indicates the retrieval of relevant documents for the question.
- CHECK RELEVANCE: Shows the process of grading the relevance of the retrieved documents.
- DECIDE TO GENERATE: Shows the decision to either transform the query or generate an answer based on document relevance.
- GENERATE: Displays the final answer generated by the CRAG system. Throughout this project, we explored how CRAG enhances the capabilities of traditional Retrieval-Augmented Generation (RAG) approaches by introducing a robust self-correction mechanism. By integrating document retrieval, relevance grading, query transformation, and web search into a unified workflow, CRAG represents a significant step forward in improving the factual accuracy and reliability of large language models.
I hope you found the guide insightful and inspiring, and I look forward to seeing how you might build upon these ideas in your own projects.