Fine-tuning Embeddings for Specific Domains: A Comprehensive Guide
Imagine you're building a question answering system for a medical domain. You want to ensure it can accurately retrieve relevant medical articles when a user asks a question. But generic embedding models might struggle with the highly specialized vocabulary and nuances of medical terminology.
That's where fine-tuning comes in !!
In this blog post, we'll delve into the process of fine-tuning an embedding model for a specific domain, like medicine, law, or finance. We'll generate a dataset specifically for your domain and use it to train the model to better understand the subtle language patterns and concepts within your chosen field.
By the end, you'll have a more powerful embedding model that's optimized for your domain, enabling more accurate retrieval and improved results for your NLP tasks.
Embeddings: Understanding the Concept
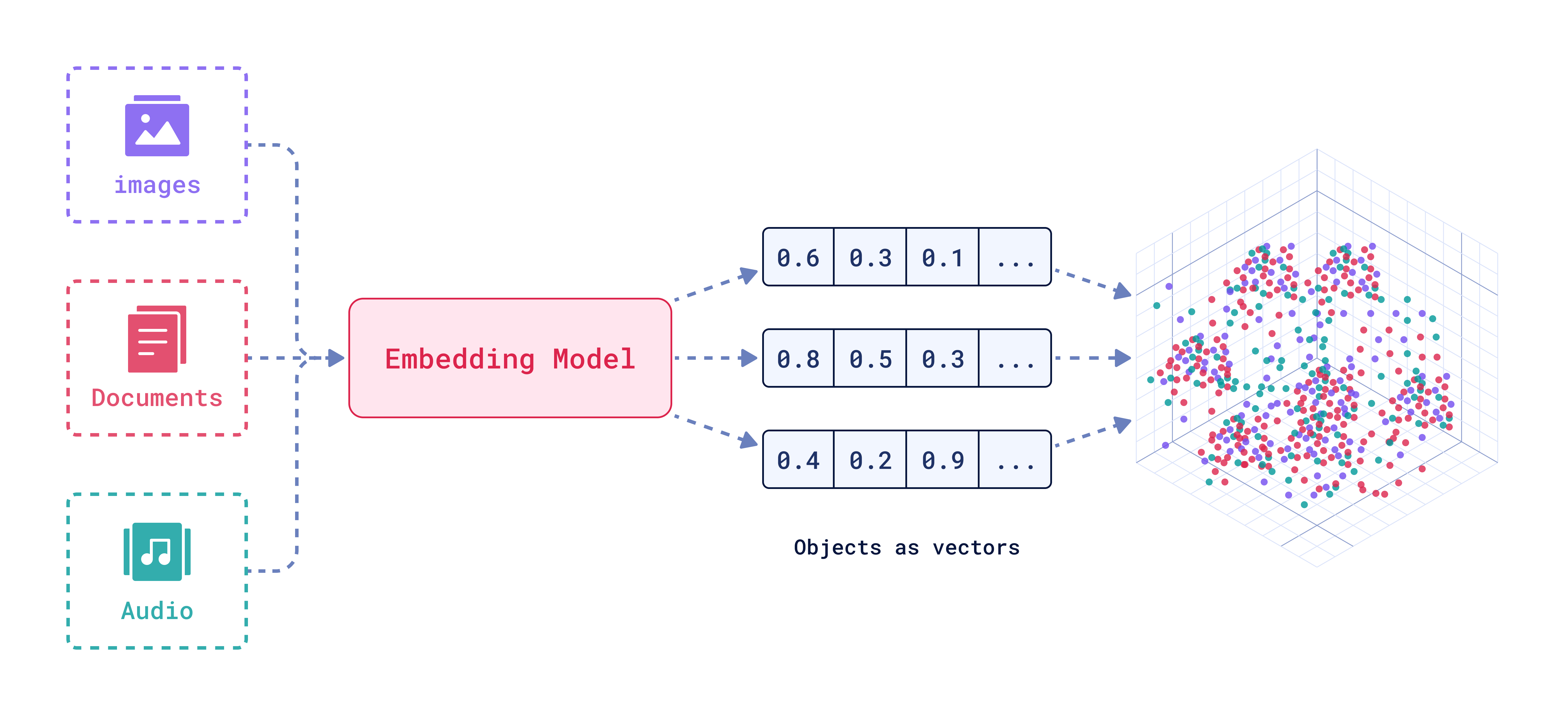
Embeddings are powerful numerical representations of text or image that capture semantic relationships. Imagine a text or audio as a point in a multi-dimensional space, where similar words or phrases are located closer together than dissimilar ones.
Embeddings are essential for many NLP tasks like :
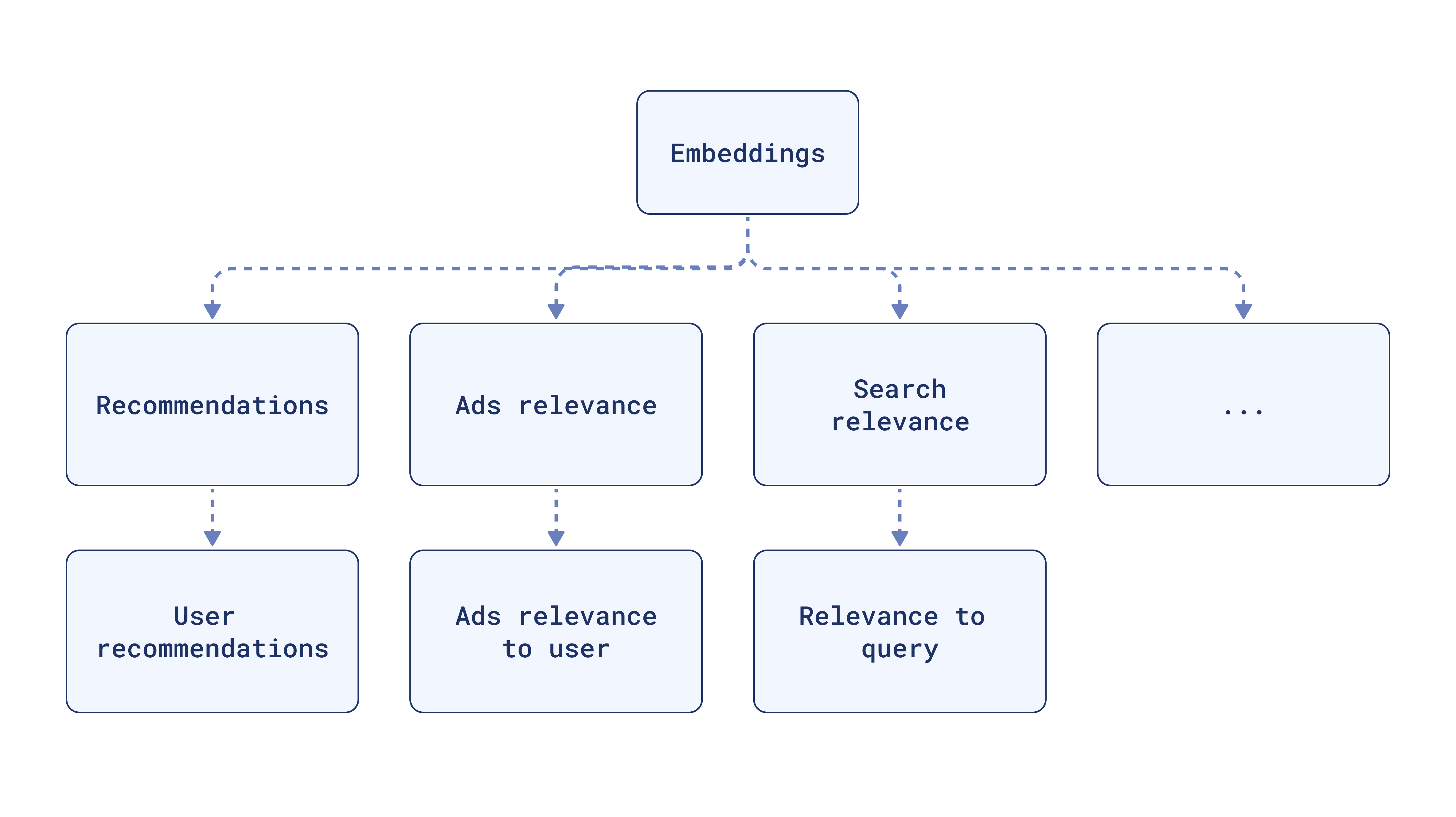
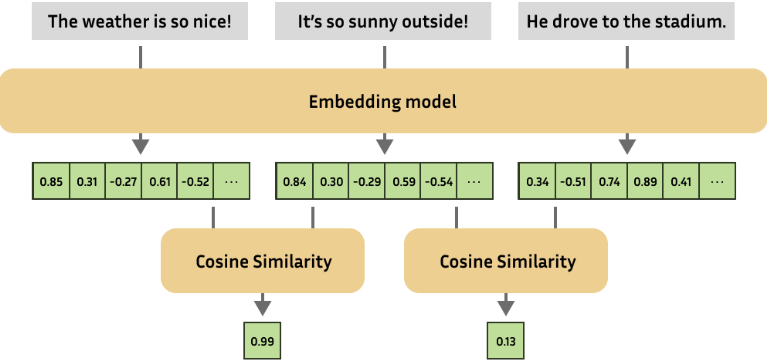
- Semantic Similarity: Finding how similar two pieces of images or text are.
- Text Classification: Grouping your data into categories based on their meaning.
- Question Answering: Finding the most relevant document to answer a question.
- Retrieval Augmented Generation (RAG): Combining an embedding model for retrieval and a language model for text generation to improve the quality and relevance of generated text.
Matryoshka Representation Learning: (Efficient Embeddings)
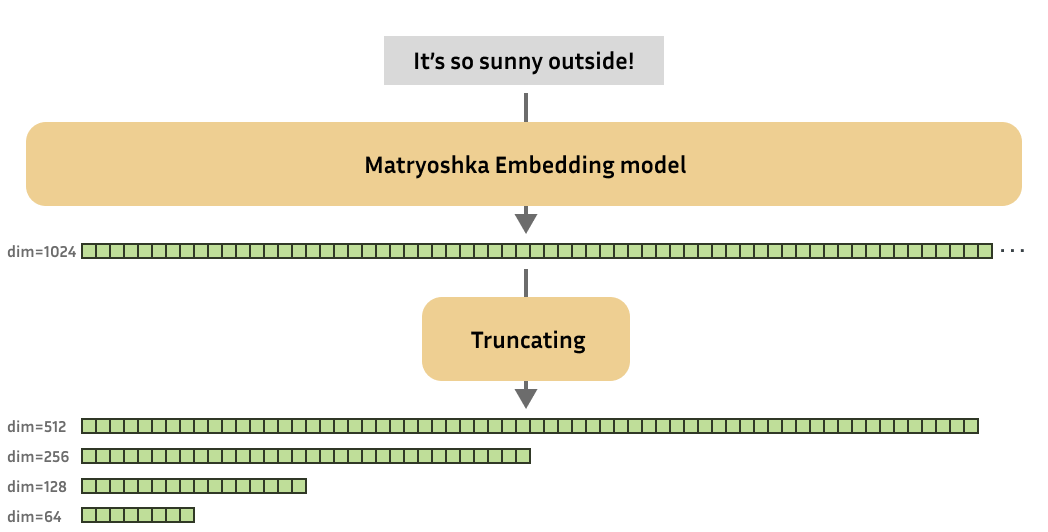
Matryoshka Representation Learning (MRL) is a technique for creating "truncatable" embedding vectors. Imagine a series of nested dolls, with each doll containing a smaller one inside. MRL embeds text in a way that the earlier dimensions (like the outer dolls) contain the most important information, and subsequent dimensions add detail. This allows you to use only a portion of the embedding vector when needed, reducing storage and computation costs.
Bge-base-en: A Powerful Embeddings Model
The BAAI/bge-base-en-v1.5 model, developed by BAAI (Beijing Academy of Artificial Intelligence), is a powerful text embedding model. It excels at various NLP tasks and has been shown to perform well on benchmarks like MTEB and C-MTEB. The bge-base-en model is a good choice for applications with limited computing resources (like my case).
Why Fine-tune Embeddings ?
Fine-tuning an embedding model for a specific domain is crucial for optimizing RAG systems. This process ensures that the model's understanding of similarity aligns with the specific context and language nuances of your domain. A fine-tuned embedding model is better equipped to retrieve the most relevant documents for a question, ultimately leading to more accurate and relevant responses from your RAG system.
Dataset Formats: Building the Foundation for Fine-tuning
You can use various dataset formats for fine-tuning.
Here are the most common types:
- Positive Pair: A pair of related sentences (e.g.,questions , answers) .
- Triplets: (anchor, positive, negative) triplets, where the anchor is similar to the positive and dissimilar to the negative.
- Pair with Similarity Score: A pair of sentences with a similarity score indicating their relationship.
- Texts with Classes: A text with its corresponding class label.
In this blog post, we will create a dataset of questions , answers pairs to fine-tune our bge-base-en-v1.5 model.
Loss Functions: Guiding the Training Process
Loss functions are crucial for training embedding models. They measure the discrepancy between the model's predictions and the actual labels, providing a signal for the model to adjust its weights.
Different loss functions are suitable for different dataset formats:
- Triplet Loss: Used with (anchor, positive, negative) triplets to encourage the model to place similar sentences closer together and dissimilar sentences farther apart.
- Contrastive Loss: Used with positive and negative pairs, encouraging similar sentences to be close and dissimilar sentences to be distant.
- Cosine Similarity Loss: Used with pairs of sentences and a similarity score, encouraging the model to produce embeddings with cosine similarities that match the provided scores.
- Matryoshka Loss: A specialized loss function designed to create Matryoshka embeddings, where the embeddings are truncatable.
Code Example
Installing Dependencies
We start with installing essential libraries. We'll use datasets, sentence-transformers, and google-generativeai for handling datasets, embedding models, and text generation.
apt-get -qq install poppler-utils tesseract-ocr
pip install datasets sentence-transformers google-generativeai
pip install -q --user --upgrade pillow
pip install -q unstructured["all-docs"]==0.12.5 pi_heif
pip install -q --upgrade unstructured
pip install --upgrade nltk
We'll also install unstructured for PDF parsing and nltk for text processing.
PDF Parsing and Text Extraction
We'll use the unstructured library to extract text and tables from PDF files.
import nltk
import os
from unstructured.partition.pdf import partition_pdf
from collections import Counter
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('punkt_tab')
def process_pdfs_in_folder(folder_path):
total_text = [] # To accumulate the text from all PDFs
# Get list of all PDF files in the folder
pdf_files = [f for f in os.listdir(folder_path) if f.endswith('.pdf')]
for pdf_file in pdf_files:
pdf_path = os.path.join(folder_path, pdf_file)
print(f"Processing: {pdf_path}")
# Apply the partition logic
elements = partition_pdf(pdf_path, strategy="auto")
# Display the types of elements
display(Counter(type(element) for element in elements))
# Join the elements to form text and add it to total_text list
text = "\n\n".join([str(el) for el in elements])
total_text.append(text)
# Return the total concatenated text
return "\n\n".join(total_text)
folder_path = "data"
all_text = process_pdfs_in_folder(folder_path)
We go through each PDF in a specified folder and partition the content into text, tables, and figures.
We then combine the text elements into a single text representation.
Custom Text Chunking
we break now the extracted text into manageable chunks using nltk. This is essential for making the text more suitable for processing by the llm.
import nltk
nltk.download('punkt')
def nltk_based_splitter(text: str, chunk_size: int, overlap: int) -> list:
"""
Splits the input text into chunks of a specified size, with optional overlap between chunks.
Parameters:
- text: The input text to be split.
- chunk_size: The maximum size of each chunk (in terms of characters).
- overlap: The number of overlapping characters between consecutive chunks.
Returns:
- A list of text chunks, with or without overlap.
"""
from nltk.tokenize import sent_tokenize
# Tokenize the input text into individual sentences
sentences = sent_tokenize(text)
chunks = []
current_chunk = ""
for sentence in sentences:
# If the current chunk plus the next sentence doesn't exceed the chunk size, add the sentence to the chunk
if len(current_chunk) + len(sentence) <= chunk_size:
current_chunk += " " + sentence
else:
# Otherwise, add the current chunk to the list of chunks and start a new chunk with the current sentence
chunks.append(current_chunk.strip()) # Strip to remove leading spaces
current_chunk = sentence
# After the loop, if there is any leftover text in the current chunk, add it to the list of chunks
if current_chunk:
chunks.append(current_chunk.strip())
# Handle overlap if it's specified (overlap > 0)
if overlap > 0:
overlapping_chunks = []
for i in range(len(chunks)):
if i > 0:
# Calculate the start index for overlap from the previous chunk
start_overlap = max(0, len(chunks[i-1]) - overlap)
# Combine the overlapping portion of the previous chunk with the current chunk
chunk_with_overlap = chunks[i-1][start_overlap:] + " " + chunks[i]
# Append the combined chunk, making sure it's not longer than chunk_size
overlapping_chunks.append(chunk_with_overlap[:chunk_size])
else:
# For the first chunk, there's no previous chunk to overlap with
overlapping_chunks.append(chunks[i][:chunk_size])
return overlapping_chunks # Return the list of chunks with overlap
# If overlap is 0, return the non-overlapping chunks
return chunks
chunks = nltk_based_splitter(text=all_text,
chunk_size=2048,
overlap=0)
Dataset Generator
In this section we define two functions:
The prompt function creates a prompt for Google Gemini, requesting a Question-Answer pair based on a provided text chunk.
import google.generativeai as genai
import pandas as pd
# Replace with your valid Google API key
GOOGLE_API_KEY = "xxxxxxxxxxxx"
# Prompt generator with an explicit request for structured output
def prompt(text_chunk):
return f"""
Based on the following text, generate one Question and its corresponding Answer.
Please format the output as follows:
Question: [Your question]
Answer: [Your answer]
Text: {text_chunk}
"""
# Function to interact with Google's Gemini and return a QA pair
def generate_with_gemini(text_chunk:str, temperature:float, model_name:str):
genai.configure(api_key=GOOGLE_API_KEY)
generation_config = {"temperature": temperature}
# Initialize the generative model
gen_model = genai.GenerativeModel(model_name, generation_config=generation_config)
# Generate response based on the prompt
response = gen_model.generate_content(prompt(text_chunk))
# Extract question and answer from response using keyword
try:
question, answer = response.text.split("Answer:", 1)
question = question.replace("Question:", "").strip()
answer = answer.strip()
except ValueError:
question, answer = "N/A", "N/A" # Handle unexpected format in response
return question, answer
The generate_with_gemini function interacts with the Gemini model and generates a QA pair using the created prompt.
Running Q&A Generation
Using the process_text_chunks function, we generate QA pairs for each text chunk using the Gemini model.
def process_text_chunks(text_chunks:list, temperature:int, model_name=str):
"""
Processes a list of text chunks to generate questions and answers using a specified model.
Parameters:
- text_chunks: A list of text chunks to process.
- temperature: The sampling temperature to control randomness in the generated outputs.
- model_name: The name of the model to use for generating questions and answers.
Returns:
- A Pandas DataFrame containing the text chunks, questions, and answers.
"""
results = []
# Iterate through each text chunk
for chunk in text_chunks:
question, answer = generate_with_gemini(chunk, temperature, model_name)
results.append({"Text Chunk": chunk, "Question": question, "Answer": answer})
# Convert results into a Pandas DataFrame
df = pd.DataFrame(results)
return df
# Process the text chunks and get the DataFrame
df_results = process_text_chunks(text_chunks=chunks,
temperature=0.7,
model_name="gemini-1.5-flash")
df_results.to_csv("generated_qa_pairs.csv", index=False)
These results are then stored in a Pandas DataFrame.
Loading the Dataset
Next, we load the generated QA pairs from the CSV file into a HuggingFace dataset. We make sure the data is in the correct format for fine-tuning.
from datasets import load_dataset
# Load the CSV file into a Hugging Face Dataset
dataset = load_dataset('csv', data_files='generated_qa_pairs.csv')
def process_example(example, idx):
return {
"id": idx, # Add unique ID based on the index
"anchor": example["Question"],
"positive": example["Answer"]
}
dataset = dataset.map(process_example,
with_indices=True ,
remove_columns=["Text Chunk", "Question", "Answer"])\
Loading the Model
We load the BAAI/bge-base-en-v1.5 model from HuggingFace, making sure to choose the appropriate device for execution (CPU or GPU).
import torch
from sentence_transformers import SentenceTransformer
from sentence_transformers.evaluation import (
InformationRetrievalEvaluator,
SequentialEvaluator,
)
from sentence_transformers.util import cos_sim
from datasets import load_dataset, concatenate_datasets
from sentence_transformers.losses import MatryoshkaLoss, MultipleNegativesRankingLoss
model_id = "BAAI/bge-base-en-v1.5"
# Load a model
model = SentenceTransformer(
model_id, device="cuda" if torch.cuda.is_available() else "cpu"
)
Defining the Loss Function
Here, we configure the Matryoshka loss function, specifying the dimensions to be used for the truncated embeddings.
# Important: large to small
matryoshka_dimensions = [768, 512, 256, 128, 64]
inner_train_loss = MultipleNegativesRankingLoss(model)
train_loss = MatryoshkaLoss(
model, inner_train_loss, matryoshka_dims=matryoshka_dimensions
)
The inner loss function, MultipleNegativesRankingLoss, helps the model produce embeddings suitable for retrieval tasks.
Defining Training Arguments
We use SentenceTransformerTrainingArguments to define the training parameters. This includes the output directory, number of epochs, batch size, learning rate, and evaluation strategy.
from sentence_transformers import SentenceTransformerTrainingArguments
from sentence_transformers.training_args import BatchSamplers
# define training arguments
args = SentenceTransformerTrainingArguments(
output_dir="bge-finetuned", # output directory and hugging face model ID
num_train_epochs=1, # number of epochs
per_device_train_batch_size=4, # train batch size
gradient_accumulation_steps=16, # for a global batch size of 512
per_device_eval_batch_size=16, # evaluation batch size
warmup_ratio=0.1, # warmup ratio
learning_rate=2e-5, # learning rate, 2e-5 is a good value
lr_scheduler_type="cosine", # use constant learning rate scheduler
optim="adamw_torch_fused", # use fused adamw optimizer
tf32=True, # use tf32 precision
bf16=True, # use bf16 precision
batch_sampler=BatchSamplers.NO_DUPLICATES, # MultipleNegativesRankingLoss benefits from no duplicate samples in a batch
eval_strategy="epoch", # evaluate after each epoch
save_strategy="epoch", # save after each epoch
logging_steps=10, # log every 10 steps
save_total_limit=3, # save only the last 3 models
load_best_model_at_end=True, # load the best model when training ends
metric_for_best_model="eval_dim_128_cosine_ndcg@10", # Optimizing for the best ndcg@10 score for the 128 dimension
)
NOTE : If you're working on a Tesla T4 and encounter errors during training, try commenting out the lines tf32=True and bf16=True to disable TF32 and BF16 precision.
Creating the Evaluator
We create an evaluator to measure the model's performance during training. The evaluator assesses the model's retrieval performance using InformationRetrievalEvaluator for each dimension in the Matryoshka loss.
corpus = dict(
zip(dataset['train']['id'],
dataset['train']['positive'])
) # Our corpus (cid => document)
queries = dict(
zip(dataset['train']['id'],
dataset['train']['anchor'])
) # Our queries (qid => question)
# Create a mapping of relevant document (1 in our case) for each query
relevant_docs = {} # Query ID to relevant documents (qid => set([relevant_cids])
for q_id in queries:
relevant_docs[q_id] = [q_id]
matryoshka_evaluators = []
# Iterate over the different dimensions
for dim in matryoshka_dimensions:
ir_evaluator = InformationRetrievalEvaluator(
queries=queries,
corpus=corpus,
relevant_docs=relevant_docs,
name=f"dim_{dim}",
truncate_dim=dim, # Truncate the embeddings to a certain dimension
score_functions={"cosine": cos_sim},
)
matryoshka_evaluators.append(ir_evaluator)
# Create a sequential evaluator
evaluator = SequentialEvaluator(matryoshka_evaluators)
Evaluating the Model Before Fine-tuning
We evaluate the base model to get a baseline performance before fine-tuning.
results = evaluator(model)
for dim in matryoshka_dimensions:
key = f"dim_{dim}_cosine_ndcg@10"
print(f"{key}: {results[key]}")
Defining the Trainer
We create a SentenceTransformerTrainer object, specifying the model, training arguments, dataset, loss function, and evaluator.
from sentence_transformers import SentenceTransformerTrainer
trainer = SentenceTransformerTrainer(
model=model, # our embedding model
args=args, # training arguments we defined above
train_dataset=dataset.select_columns(
["positive", "anchor"]
),
loss=train_loss, # Matryoshka loss
evaluator=evaluator, # Sequential Evaluator
)
Starting Fine-tuning
The trainer.train() method starts the fine-tuning process, updating the model's weights using the provided data and loss function.
# start training
trainer.train()
# save the best model
trainer.save_model()
Once training is done, we save the best-performing model to the specified output directory.
Evaluating After Fine-tuning
Finally, we load the fine-tuned model and evaluate it using the same evaluator to measure the improvement in performance after fine-tuning.
from sentence_transformers import SentenceTransformer
fine_tuned_model = SentenceTransformer(
args.output_dir, device="cuda" if torch.cuda.is_available() else "cpu"
)
# Evaluate the model
results = evaluator(fine_tuned_model)
# Print the main score
for dim in matryoshka_dimensions:
key = f"dim_{dim}_cosine_ndcg@10"
print(f"{key}: {results[key]}")
By fine-tuning an embedding model for your domain, you equip your NLP applications with a deeper understanding of the specific language and concepts within that field. This can lead to significant improvements in tasks like question answering, document retrieval, and text generation.
The techniques discussed in this blog post, such as leveraging Matryoshka Representation Learning and using a powerful model like bge-base-en, offer a practical path towards building domain-specific embedding models. While we've focused on the process of fine-tuning, remember that the quality of your dataset is equally crucial. Carefully curating a dataset that accurately reflects the nuances of your domain is essential for achieving optimal results.
As the field of NLP continues to advance, we can expect to see even more powerful embedding models and fine-tuning strategies emerge. By staying informed and adapting your approach, you can harness the full potential of embedding models for building high-quality NLP applications tailored to your specific needs.
Happy Tuning .