Down-Scaling and Depth Up-Scaling Techniques
LLM Down-Scaling
LLM Down-Scaling is an innovative approach that focuses on reducing the complexity and size of large language models while maintaining their performance and capabilities . \
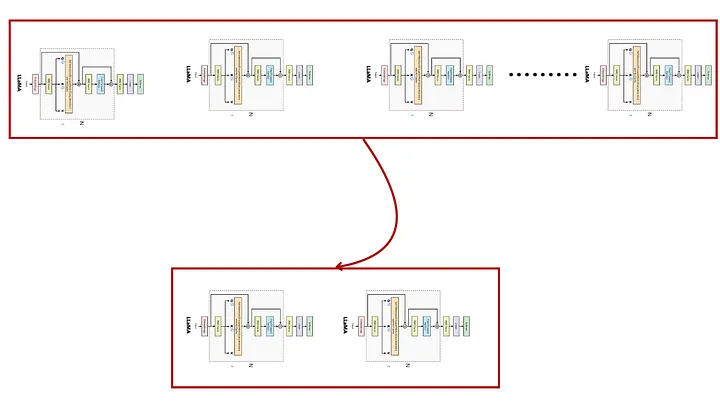
This technique involves strategically pruning layers, reducing parameters, and employing efficient training methods to create more compact and resource-efficient models , by down-scaling LLMs, researchers aim to make advanced language models accessible for deployment in resource-constrained environments, such as edge devices and mobile applications, without sacrificing the model’s ability to perform complex language understanding and generation tasks , this approach not only enhances computational efficiency but also reduces energy consumption and operational costs, making sophisticated AI tools more sustainable and widely usable.
Depth Up-Scaling
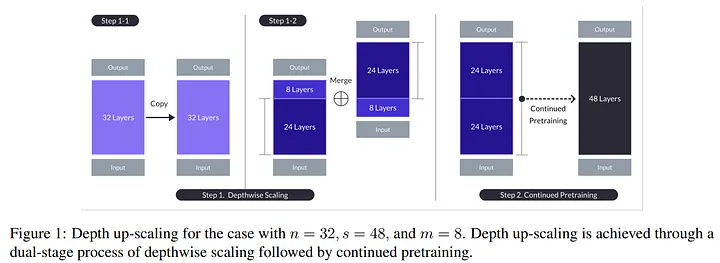
Depth Up-Scaling (DUS) is a novel approach designed to enhance the capabilities of base models by up-scaling their depth , this process involves removing and adding layers to the base model to optimize its performance and efficiency , the primary goal of DUS is to achieve a balance between computational efficiency and model performance, addressing the limitations posed by existing hardware and software constraints.
Key Features and Architectural Insights
The architecture of DUS is built upon the foundation of large language models , leveraging the scaling laws that correlate model size with performance.
Layer manipulation: depth up-scaling involves the strategic removal and addition of layers, in the discussed study, eight layers were removed from both ends of the base model , this manipulation aims to streamline the model, reducing computational demands while retaining essential information.
Emergent abilities: DUS enables models to exhibit emergent abilities such as zero-shot and few-shot learning , these abilities allow models to perform new tasks without updating their weights, a feature not evident in smaller models.
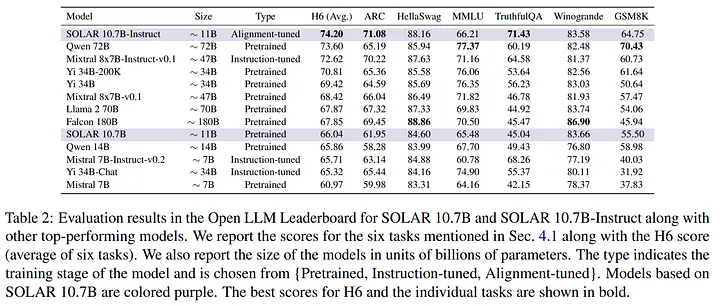
The performance of DUS was evaluated using various benchmarks and datasets , notably the SOLAR 10.7B and SOLAR 10.7B-Instruct models demonstrated exceptional performance, outperforming other pretrained models of similar sizes , the evaluation utilized six types of datasets: ARC, HellaSWAG, MMLU, TruthfulQA, Winogrande, and GSM8K, providing a comprehensive assessment of model capabilities.
Now that we’ve covered some theory behind down-scaling and depth up-scaling, it’s time to get our hands dirty with some code , we’ll dive into practical examples, demonstrating how to implement these techniques to optimize our models , by walking through the code, we’ll see exactly how to trim down a large model for efficiency and how to strategically add layers to enhance its capabilities , this hands-on approach will solidify our understanding and pave the way for creating an advanced algerian darija-speaking model , let’s turn theory into practice and start coding .
Code Time
We use deepcopy for creating independent model copies, transformers for tokenization and model configuration, and PyTorch (torch and torch.nn as nn) for building and modifying neural network layers .
from copy import deepcopy
from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM
import torch
import torch.nn as nn
Define print_nparamsfunction calculates and prints the total number of parameters in a given model.
def print_nparams(model):
"""Calculate the total number of model parameters"""
nparams = sum(p.numel() for p in model.parameters())
print(f"The total number of parameters is: {nparams}")
It sums up the number of elements (parameters) in each layer of the model using sum(p.numel() for p in model.parameters(), providing a straightforward way to assess the model's size and complexity, which is crucial for both Down-Scaling and Depth Up-Scaling efforts.
Downscaling
The downscale_model function trims a pre-trained model by retaining only specified top and bottom layers, thus reducing its depth and size for efficiency , it begins by loading the model and tokenizer from a checkpoint .
def downscale_model(model_name_or_path, top_layers, bottom_layers, save=False , device_map="auto"):
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
device_map=device_map,
torch_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
# Modify model layers
layers = model.model.layers
model.model.layers = layers[:top_layers] + layers[-bottom_layers:]
# Update model configuration
config = AutoConfig.from_pretrained(
model_name_or_path,
num_hidden_layers=len(model.model.layers),
)
model.config = config
print_nparams(model)
# Save model if requested
if save:
model.save_pretrained(f"{model_name_or_path.split('/')[-1]}_downscaled")
tokenizer.save_pretrained(f"{model_name_or_path.split('/')[-1]}_downscaled")
print(f"Model and tokenizer saved to {model_name_or_path.split('/')[-1]}_downscaled")
return model
The function then modifies the model by keeping the first top_layers and the last bottom_layers, discarding the rest , the model's configuration is updated to reflect the new layer count, and the total number of parameters is printed with the print_nparams function , if requested the down-scaled model and tokenizer are saved to a new directory , this method optimizes the model by balancing performance and computational efficiency, as per our down-scaling theory.
Example usage:
model_name_or_path = "Qwen/Qwen2-0.5B-Instruct"
downscaled_model = downscale_model(model_name_or_path=model_name_or_path,
top_layers=4,
bottom_layers=4,
save=True ,
device_map="auto") # you can use cuda or ( cpu for small model like this case )
print_nparams(downscaled_model)
Depth Upscaling
The depth_upscale_model function enhances a base model by adding layers from other models, increasing its depth and complexity , it starts by loading the base model and tokenizer, the function then initializes a list to store layers from other models specified in models_with_layers, each providing top and bottom layers to be copied , these layers are added to the base model sequentially .
def depth_upscale_model(base_model_name_or_path, models_with_layers, save=False , device_map="auto"):
# Load base model and tokenizer
base_model = AutoModelForCausalLM.from_pretrained(
base_model_name_or_path,
device_map=device_map,
torch_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(base_model_name_or_path)
# Initialize an empty list for layers to copy
layers_to_copy = []
for model_name_or_path, top_layers, bottom_layers in models_with_layers:
# Load the model to copy layers from
model_to_copy_from = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
device_map=device_map,
torch_dtype=torch.bfloat16,
)
# Add the specified top and bottom layers to the list
layers_to_copy.extend(deepcopy(model_to_copy_from.model.layers[:top_layers]))
layers_to_copy.extend(deepcopy(model_to_copy_from.model.layers[-bottom_layers:]))
# Copy the embedding and lm_head layers from the first model only
if not hasattr(base_model.model, 'embed_tokens'):
base_model.model.embed_tokens = deepcopy(model_to_copy_from.model.embed_tokens)
if not hasattr(base_model, 'lm_head'):
base_model.lm_head = deepcopy(model_to_copy_from.lm_head)
# Create a new Sequential module with the copied layers
base_model.model.layers = nn.ModuleList(layers_to_copy)
# Update base model configuration
config = AutoConfig.from_pretrained(
base_model_name_or_path,
num_hidden_layers=len(base_model.model.layers),
)
base_model.config = config
# Save model if requested
if save:
save_path = f"{base_model_name_or_path}_depth_upscaled"
base_model.save_pretrained(save_path)
tokenizer.save_pretrained(save_path)
print(f"Model and tokenizer saved to {save_path}")
return base_model
The embedding and language modeling head layers are copied from the first model only , the base model’s configuration is updated to reflect the new layer count , if specified, the upscaled model and tokenizer are saved to a new directory , this method boosts the model’s performance by integrating additional layers, aligning with our depth up-scaling strategy.
Example usage:
base_model_name = "Qwen/Qwen2-0.5B-Instruct"
models_with_layers = [
("Qwen/Qwen2-0.5B-Instruct", 4, 4), # Model name, top layers to copy, bottom layers to copy
("Qwen/Qwen2-0.5B-Instruct", 4, 4),
# Add more models as needed
]
# Call the function directly
upscaled_model = depth_upscale_model(base_model_name,
models_with_layers )
print_nparams(upscaled_model)
Down-scaling helps us slim down our models so they run smoothly on devices with less power, while up-scaling lets us pump up the model’s capabilities by adding more layers, making it smarter and more powerful (not always).
However research has shown that implementing these techniques isn’t a one-and-done deal , they often require continual pre-training and adjustments to get the best results. As we move forward in our journey to build a model that can fluently speak algerian darija, we’ll keep this in mind and continue refining our approach , thanks for joining me on this adventure — there’s much more to come as we push the boundaries of what’s possible .