Building a robust GraphRAG System for specific use case -Part Two-
Part Two: The Fine-Tuning Process
In the first part of this series, we embarked on the crucial task of preparing a custom dataset for fine-tuning a large language model (LLM) for text-to-Cypher translation. We generated a diverse set of questions tailored to our specific Neo4j graph database schema and then leveraged another LLM to translate these questions into their corresponding Cypher queries. This process resulted in a high-quality dataset of question-Cypher pairs, which will serve as the foundation for fine-tuning our target LLM in this part.
Fine-Tuning Llama 3.1 with QLoRA
Our objective in this part is to fine-tune a Llama 3.1 8b model using the dataset generated in the previous step. To achieve this efficiently, we will leverage one of the Parameter-Efficient Fine-Tuning (PEFT) methods called QLoRA (Quantized Low-Rank Adaptation), implemented using the Unsloth framework.
PEFT (Parameter-Efficient Fine-Tuning)
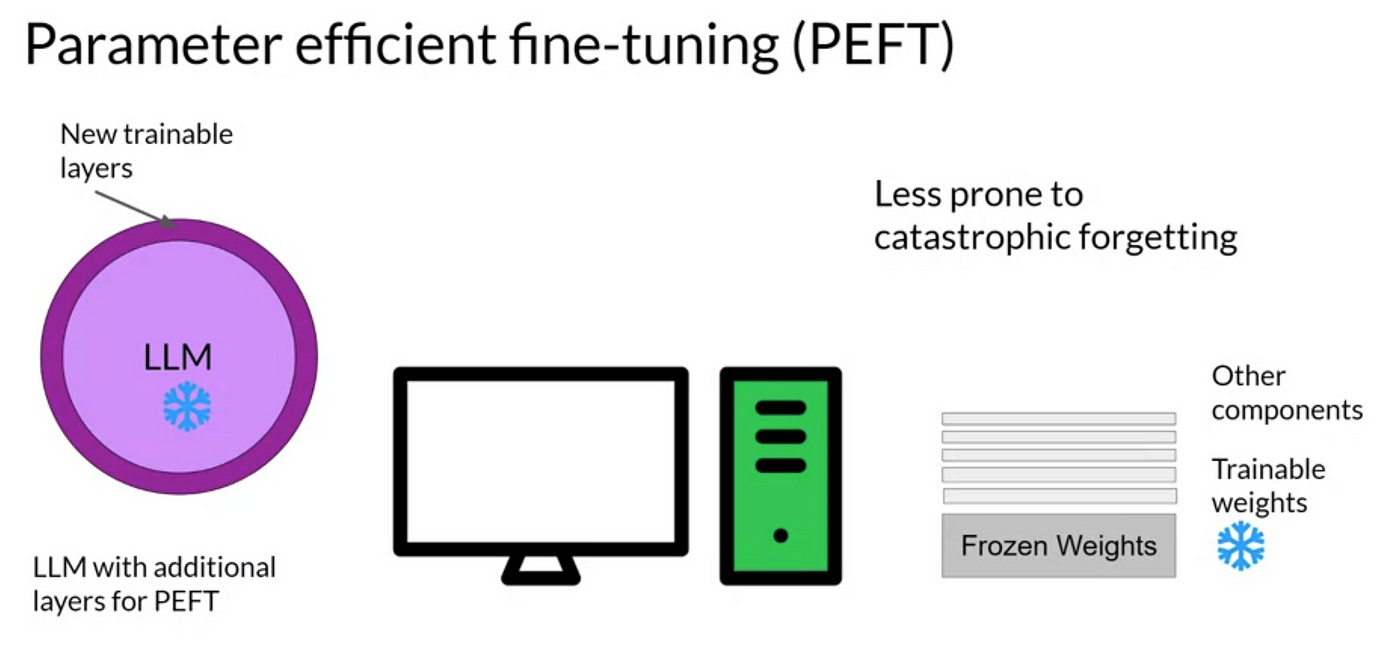
Parameter-Efficient Fine-Tuning (PEFT) techniques address the challenge of fine-tuning large language models, which can be computationally expensive and require significant memory resources. Instead of updating all the parameters of a pre-trained LLM, PEFT methods modify only a small subset of parameters, typically those that have the most significant impact on the target task. This approach drastically reduces the computational burden and memory footprint of the fine-tuning process, making it feasible to fine-tune large LLMs even on resource-constrained hardware.
QLoRA (Quantized Low-Rank Adaptation)
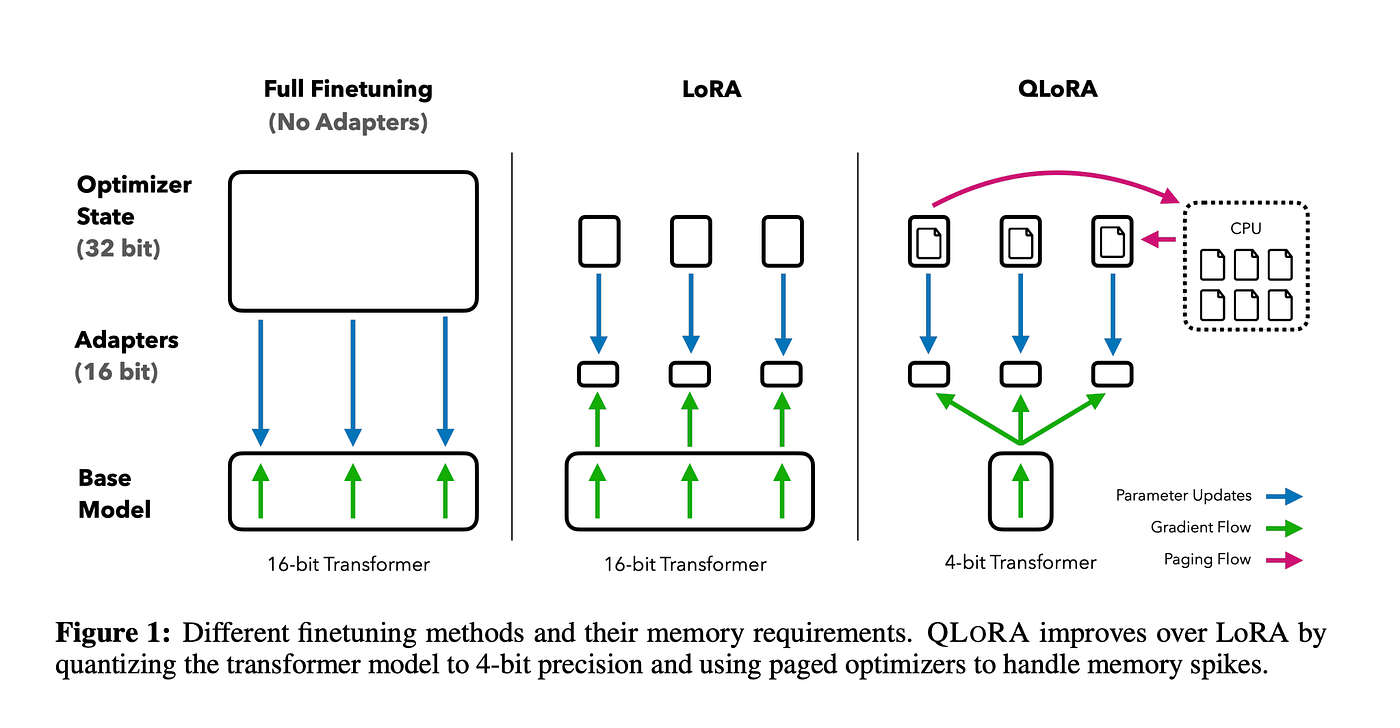
QLoRA is a particularly efficient PEFT technique that combines the benefits of Low-Rank Adaptation (LoRA) with quantization. LoRA fine-tunes models by adding small, low-rank matrices to the existing layers, effectively injecting task-specific knowledge without modifying the original model's weights. QLoRA further enhances this approach by applying 4-bit quantization to the pre-trained model's weights, drastically reducing memory consumption while maintaining performance comparable to full 16-bit fine-tuning. This combination of techniques allows for fine-tuning large LLMs, such as Llama 3.1, on relatively modest hardware, even a single GPU with limited memory.
Unsloth Framework

The Unsloth framework is an open-source solution designed to streamline and simplify the fine-tuning and training of LLMs like Llama 3, Mistral, and Gemma. Developed by a team with experience at NVIDIA, Unsloth focuses on making the fine-tuning process faster, more efficient, and less resource-intensive. It achieves this by incorporating advanced techniques like LoRA and quantization, providing a user-friendly interface, and offering seamless integration with popular tools like Google Colab.
Unsloth's primary goal is to democratize the creation of custom AI models, enabling developers to efficiently build and deploy models tailored to specific needs, regardless of their computational resources. By utilizing Unsloth, we can leverage the power of QLoRA to fine-tune our Llama 3.1 model for text-to-Cypher translation effectively and efficiently.
Installing Dependencies
Here we install the necessary packages for fine-tuning.
# Installs Unsloth, Xformers (Flash Attention) and all other packages!
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
# We have to check which Torch version for Xformers (2.3 -> 0.0.27)
from torch import __version__; from packaging.version import Version as V
xformers = "xformers==0.0.27" if V(__version__) < V("2.4.0") else "xformers"
!pip install --no-deps {xformers} trl peft accelerate bitsandbytes triton
Loading the Model
Here we load the pre-trained Llama 3.1 8B model and its tokenizer using the FastLanguageModel class from Unsloth. We specify the maximum sequence length (max_seq_length) to restrict the model's context window, which impacts both compute and memory usage.
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # to restricts its context window, most of model support larger, but make sure to use it based on your need since it will consumes more compute and VRAM
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
We set the data type (dtype) to None for automatic detection, or we can explicitly choose float16 for older GPUs or bfloat16 for newer Ampere GPUs. We enable 4-bit quantization (load_in_4bit) to reduce memory usage during fine-tuning.
Configuring the Model for Training
Here we prepare the loaded model for PEFT using QLoRA. We use the get_peft_model function to apply LoRA to specific layers of the model. We define the rank (r) of the LoRA matrices, which determines the number of trainable parameters. Higher ranks can store more information but increase computational and memory costs.
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Suggested 8, 16, 32, 64, 128, higher ranks can store more information but increase the computational and memory cost of LoRA.
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16, # rule of thumb, double the r or equal. alpha is a scaling factor for updates
lora_dropout = 0, # Supports any, but = 0 is optimized. Probability of zeroing out elements in low-rank matrices for regularization.
random_state = 3407,
use_rslora = True, # has been proven to work better ( https://arxiv.org/pdf/2312.03732 )
)
We specify the target_modules, which are the layers where LoRA will be applied. We set lora_alpha (scaling factor for updates), lora_dropout (probability of dropout for regularization), and random_state for reproducibility. We also enable use_rslora, which has been shown to improve performance.
Instruction Tuning Prompt Formatter
Here we define the prompt format and a function for preparing training data. We use the Alpaca format, which consists of an instruction, input, and response. We customize the instruction to guide the model to convert text to Cypher queries based on the provided graph schema.
prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
instructions = f"Convert text to cypher query based on this schema: {graph.schema}" # examples["instructions"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for input, output in zip(inputs, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = prompt.format(instructions, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
The formatting_prompts_func takes a dataset of examples and formats them according to the Alpaca prompt template, adding the end-of-sequence token (EOS_TOKEN) to ensure proper termination of the generated sequences.
Loading and Preparing the Dataset
Here we load the dataset generated in the first part, filter out rows with syntax errors or timeouts, and rename the columns to match the expected format for the fine-tuning process.
import pandas as pd
df = pd.read_csv('final_text2cypher.csv')
df = df[(df['syntax_error'] == False) & (df['timeout'] == False)]
df = df[['question','cypher']]
df.rename(columns={'question': 'input','cypher':'output'}, inplace=True)
df.reset_index(drop=True, inplace=True)
We then convert the Pandas DataFrame into a Hugging Face Dataset object and apply the formatting_prompts_func to format the examples according to the Alpaca prompt template.
from datasets import Dataset
dataset = Dataset.from_pandas(df)
dataset = dataset.map(formatting_prompts_func, batched = True)
Creating the Supervised Fine-Tuning Trainer
Here we create the SFTTrainer from the TRL library to fine-tune the model using the prepared dataset. We provide the model, tokenizer, training dataset, text field name, maximum sequence length, and other configurations.
from trl import SFTTrainer
from transformers import TrainingArguments
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
# max_steps = 60,
num_train_epochs=1,
learning_rate = 2e-4, # the rate at which the model updates its parameters during training.
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)
We use the TrainingArguments class from Transformers to define the training parameters, including batch size, gradient accumulation steps, warmup steps, learning rate, optimizer, weight decay, and other hyperparameters.
Starting the Training
trainer_stats = trainer.train()
This will start the training loop, iterating over the training dataset and updating the model's parameters based on the defined training arguments.
Inference
Here we enable native faster inference for the fine-tuned model and define a function for generating Cypher queries.
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
def generate_cypher_query(question):
inputs = tokenizer(
[
prompt.format(
f"Convert text to cypher query based on this schema: {graph.schema}", # instruction
question, # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 64, use_cache = True)
result = tokenizer.batch_decode(outputs)
cypher_query = result[0].split("### Response:")[1].split("###")[0].strip().replace("<|end_of_text|>", "").replace("<eos>", "").replace("{{", "{").replace("}}", "}")
return cypher_query
question = "Write your question here .."
cypher_query = generate_cypher_query(question)
The generate_cypher_query function takes a natural language question as input, formats it according to the Alpaca prompt template, and uses the fine-tuned model to generate a Cypher query. The generated query is then extracted from the model's output and cleaned up.
Saving the Model
Here we save the fine-tuned model in the GGUF format. We can choose to save the model in 8-bit quantized format (Q8_0), 16-bit format (f16), or other quantized formats like q4_k_m, depending on the desired trade-off between model size and performance.
# Save to 8bit Q8_0
if True: model.save_pretrained_gguf("model", tokenizer,)
# or Save to 16bit GGUF
if False: model.save_pretrained_gguf("model", tokenizer, quantization_method = "f16")
# or Save to q4_k_m GGUF
if False: model.save_pretrained_gguf("model", tokenizer, quantization_method = "q4_k_m") # you can use any other format not only "q4_k_m"
Deploying the Model and Creating an OpenAI-Compatible API Endpoint

Installing and Creating the Model with Ollama
Here we install Ollama, a tool for serving LLMs .
curl -fsSL https://ollama.com/install.sh | sh
And create a Modelfile that specifies the path to the saved GGUF model.
touch Modelfile
The Modelfile containg:
FROM /path/to/model.gguf
We then use the ollama create command to build the model for serving.
ollama create llama3.1-cypher
Starting the Server
Here we start the Ollama server, which will make the fine-tuned model accessible via an API endpoint.
ollama serve
Testing the API
Here we demonstrate how to interact with the deployed model using the OpenAI API client. We initialize the client with the URL of the Ollama server and send a chat completion request with a natural language question.
# pip install openai
from openai import OpenAI
client = OpenAI(
base_url = 'http://127.0.0.1:11434/v1',
api_key='ollama', # required, but unused
)
response = client.chat.completions.create(
model="llama3.1-cypher",
messages=[
{"role": "user", "content": "Write your question here .. "},
]
)
print(response.choices[0].message.content)
The server will use the fine-tuned model to generate a Cypher query and return it as part of the API response.
With our Llama 3.1 model now fine-tuned and deployed as an OpenAI-compatible API endpoint, we possess a powerful tool for translating natural language questions into Cypher queries. This capability lays the groundwork for building a sophisticated question-answering system capable of extracting valuable insights from our graph database. In the final part of this series, we'll explore how to integrate this fine-tuned model with a knowledge extraction component to create a comprehensive Q&A system that empowers users to interact with their data using natural language. Join us as we complete the journey from raw data to insightful answers.