Simple Ways to Parse PDFs for Better RAG Systems
In Retrieval-Augmented Generation (RAG) systems, the quality of the output is intricately linked to the quality of the input data, exemplifying the "garbage in, garbage out" principle. RAG systems leverage Large Language Models (LLMs) in conjunction with external data retrieval to produce more precise responses. Yet, even the most advanced LLMs can only deliver accurate results if the documents they process are well-structured and correctly parsed.
Recent innovations in tools like LlamaParse and Marker-PDF address this challenge by providing intelligent PDF parsing that preserves context, sections, and layout integrity. These tools decompose complex documents into coherent, relevant chunks, ensuring that the data fed into LLMs is both accurate and meaningful. By emphasizing high-quality data extraction, these tools mitigate the risks of incorrect or misleading outputs in RAG systems.
In this blog post, we will delve into effective methods for parsing PDFs to optimize your RAG applications, ensuring they can manage even the most intricate documents with precision and ease.
Nougat Model, Small-Sized Version
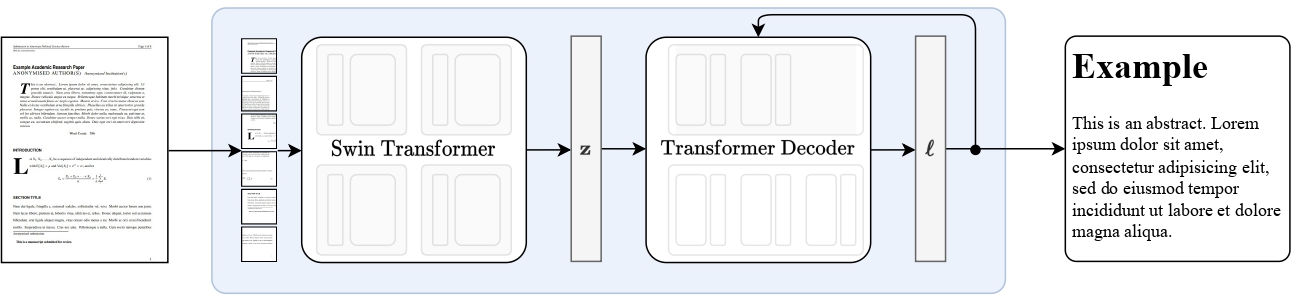
The Nougat model, specifically the "0.1.0-small" version, is a compact variant of the model introduced in the paper "Nougat: Neural Optical Understanding for Academic Documents" by Blecher et al. This version is designed for efficient PDF-to-markdown conversion and was first made available in the repository associated with the paper.
Model Description:
Nougat employs the Donut architecture for transcribing scientific PDFs into a markdown format. It utilizes a Swin Transformer as the vision encoder to process the visual content of the PDF and an mBART model as the text decoder to generate the markdown output. The model is trained to autoregressively predict the markdown content directly from the PDF's image pixels, allowing for accurate and structured representation of scientific documents in an accessible format.
Usage
Installing Required Packages and Tools:
pip install -q pdf2image
apt-get install poppler-utils
Loading the Nougat Model:
In this block, we load the Nougat model and its associated processor from the Hugging Face model hub. The AutoProcessor and VisionEncoderDecoderModel classes are used to initialize the model and processor.
from transformers import AutoProcessor, VisionEncoderDecoderModel
import torch
# Load the Nougat model and processor from the hub
processor = AutoProcessor.from_pretrained("facebook/nougat-small")
model = VisionEncoderDecoderModel.from_pretrained("facebook/nougat-small")
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
The model is moved to a GPU if available; otherwise, it defaults to the CPU.
Converting PDFs to Images:
Here, we define a function to convert PDF files from a specified folder into images. The convert_from_path function from pdf2image is used to convert each page of a PDF into an image.
from pdf2image import convert_from_path
import os
def convert_pdfs_to_images(folder_path):
images = []
# List all files in the folder
for filename in os.listdir(folder_path):
# Check if the file is a PDF
if filename.endswith(".pdf"):
pdf_path = os.path.join(folder_path, filename)
# Convert PDF to list of images
pdf_images = convert_from_path(pdf_path)
images.extend(pdf_images) # Add all images to the main list
return images
folder_path = "pdfs"
all_images = convert_pdfs_to_images(folder_path)
All images from all PDFs in the folder are collected into a single list.
Processing Images into Pixel Values:
In this step, we prepare the images for input into the Nougat model. Each image is processed by the AutoProcessor, which converts it into pixel values formatted for the model.
pixel_values = [processor(images=all_images[i] , return_tensors="pt").pixel_values for i in range(len(all_images))]
These pixel values are stored in a list for subsequent processing.
Generating Markdown from Images:
We process each image pixel value through the Nougat model to generate markdown. The model.generate method is used to produce the markdown text. The generated text is then decoded and post-processed to fix markdown formatting issues.
from tqdm import tqdm
markdown = ""
for pixel_value in tqdm(pixel_values, desc="Processing images"):
pixel_value = pixel_value.to(device)
outputs = model.generate(
pixel_value,
min_length=1,
max_new_tokens=4096,
bad_words_ids=[[processor.tokenizer.unk_token_id]],
)
sequence = processor.batch_decode(outputs, skip_special_tokens=True)[0]
sequence = processor.post_process_generation(sequence, fix_markdown=True)
markdown += sequence
All generated markdown sequences are concatenated into a single markdown string.
Displaying the Markdown Output:
Finally, we use the IPython.display library to display the resulting markdown.
from IPython.display import display, Markdown
display(Markdown(markdown))
The Markdown class is used to render the text in a markdown format, providing a structured view of the content extracted from the PDFs.
Marker: Efficient PDF to Markdown Conversion
Marker is an advanced tool designed to convert PDFs to Markdown quickly and accurately. It's optimized for a wide range of documents, particularly books and scientific papers, and supports all languages. Marker excels at removing unwanted artifacts like headers and footers, formatting tables and code blocks, and even converting most equations to LaTeX. It also extracts and saves images along with the markdown, ensuring that the integrity of the original document is maintained.
Marker achieves this through a pipeline of deep learning models that handle text extraction, OCR, page layout detection, block formatting, and post-processing. By only using models where necessary, Marker enhances both speed and accuracy in processing.
For those looking to integrate this capability into their workflows, the Marker API provides a simple endpoint for converting PDF documents to Markdown. With support for multiple PDFs at once, the API makes it easy to handle complex documents on GPU, CPU, or MPS.

Usage
Installing the Marker-PDF Tool:
Here, we start by installing the marker-pdf package using pip. This is the core tool we'll use for converting PDF files into Markdown format.
pip install marker-pdf
Converting a Single PDF File:
After installation, we create an output directory and then use the marker_single command to convert a single PDF file into Markdown. The converted file will be saved in the specified output directory.
mkdir output
marker_single /path/file.pdf /path/output
You can also adjust the conversion parameters using various options, like increasing the batch size for faster processing if you have extra VRAM.
--batch_multiplieris how much to multiply default batch sizes by if you have extra VRAM. Higher numbers will take more VRAM, but process faster. Set to 2 by default. The default batch sizes will take ~3GB of VRAM.--max_pagesis the maximum number of pages to process. Omit this to convert the entire document.--langsis an optional comma separated list of the languages in the document, for OCR. Optional by default, required if you use tesseract.--ocr_all_pagesis an optional argument to force OCR on all pages of the PDF. If this or the env varOCR_ALL_PAGESare true, OCR will be forced.
Converting Multiple PDF Files:
Here, we demonstrate how to convert multiple PDFs at once using the marker command. This method allows you to specify the number of workers for parallel processing, which speeds up the conversion but requires more resources.
marker /path/data /path/output --workers 4
As with the single-file conversion, additional options are available to control the conversion process, such as setting a maximum number of files to convert or filtering out PDFs based on content length.
--workersis the number of pdfs to convert at once. This is set to 1 by default, but you can increase it to increase throughput, at the cost of more CPU/GPU usage. Marker will use 5GB of VRAM per worker at the peak, and 3.5GB average.--maxis the maximum number of pdfs to convert. Omit this to convert all pdfs in the folder.--min_lengthis the minimum number of characters that need to be extracted from a pdf before it will be considered for processing. If you're processing a lot of pdfs, I recommend setting this to avoid OCRing pdfs that are mostly images. (slows everything down)--metadata_fileis an optional path to a json file with metadata about the pdfs.
Retrieving the Output:
Once the conversion is complete, you'll find the extracted Markdown files and images neatly organized in the output folder.
LlamaParse: GenAI-Native Document Parsing for Enhanced LLM Performance
LlamaParse is a cutting-edge document parsing platform built specifically for Large Language Model (LLM) applications. Understanding that the quality of data directly influences the performance of LLMs, LlamaParse is designed to clean and structure your data before it’s passed downstream, especially for advanced Retrieval-Augmented Generation (RAG) tasks.
Key features of LlamaParse include state-of-the-art table extraction, natural language instructions for custom output formatting, JSON mode, and image extraction. It supports over 10 file types, including PDFs, PPTX, DOCX, HTML, and XML, and offers foreign language support.
LlamaParse integrates seamlessly with LlamaIndex, allowing for efficient retrieval and context augmentation. It’s available as a standalone API with a free plan supporting up to 1,000 pages per day, making it accessible for a variety of use cases. For those handling complex, semi-structured documents with embedded objects like tables and figures, LlamaParse provides proprietary parsing capabilities that unlock advanced RAG possibilities, enabling you to answer intricate questions that were previously out of reach.
Usage
Installing LlamaParse:
Here we begin by installing the llama-index and llama-parse packages using pip.
pip install llama-parse llama-index
This will be our primary tool for parsing and extracting data from various document formats, particularly PDFs.
Setting Up for Jupyter Notebook:
If you're running this code in a Jupyter Notebook, uncomment the following lines. Here we use nest_asyncio to allow nested event loops, which is necessary for running asynchronous code in a Jupyter environment.
import nest_asyncio
nest_asyncio.apply()
Single File Parsing:
Here we demonstrate how to initialize the LlamaParse object with your API key and set the result type to either "markdown" or "text".
from llama_parse import LlamaParse # pip install llama-parse
parser = LlamaParse(
api_key="API_key", # can also be set in your env as LLAMA_CLOUD_API_KEY
result_type="markdown" # "markdown" and "text" are available
)
# sync
documents = parser.load_data("./my_file.pdf")
# async
# documents = await parser.aload_data("./my_file.pdf")
We then show how to load data from a PDF file, both synchronously and asynchronously. Remember to replace API_key with your actual API key, which you can obtain from the LlamaIndex cloud platform.
Parsing Multiple Files with LlamaIndex Integration:
In this block, we integrate LlamaParse with the SimpleDirectoryReader from LlamaIndex. After setting up the LlamaParse instance with the desired result type, we map it to a specific file extension, in this case, .pdf.
from llama_parse import LlamaParse # pip install llama-parse
from llama_index.core import SimpleDirectoryReader # pip install llama-index
parser = LlamaParse(
api_key="API_key", # can also be set in your env as LLAMA_CLOUD_API_KEY
result_type="markdown" # "markdown" and "text" are available
)
file_extractor = {".pdf": parser}
reader = SimpleDirectoryReader("./data", file_extractor=file_extractor)
documents = reader.load_data()
The SimpleDirectoryReader then uses this mapping to parse and load data from all matching files within the specified directory.
Printing the Parsed Document Text:
Finally, we loop through the parsed documents and print out their text content.
for i in range(len(documents)) :
print(documents[i].text)
This gives us a clear view of the extracted data, which can now be used for further processing or analysis.
Using Gemini Flash for Data Extraction and PDF Parsing

For data extraction and PDF parsing, we'll utilize Gemini Flash, a lightweight and optimized model by Google. This model is designed for efficiency and speed, boasting a one-million-token context window by default. This capability allows it to handle extensive content such as long videos, audio recordings, or large codebases effectively.
Gemini 1.5 Flash is particularly favored by developers for high-volume, low-latency applications like summarization, categorization, and multi-modal understanding. As of August 12, pricing for Gemini 1.5 Flash has been significantly reduced, making it more cost-effective. The input price has dropped by 78% to $0.075 per million tokens, and the output price by 71% to $0.3 per million tokens for prompts under 128K tokens. These reductions, combined with tools like context caching, enable developers to achieve substantial cost savings while leveraging Gemini 1.5 Flash’s extensive context and multimodal features.
Usage
Installing the Google Generative AI Library:
Here we install the google-generativeai package using pip.
pip install google-generativeai
This library allows us to interact with Google's generative AI models, which we will use for document extraction and parsing.
Configuring the Google Generative AI Library:
Next, we import the google.generativeai module and configure it with an API key.
import google.generativeai as genai
api_key="xxxxxxxxxxxxxx"
genai.configure(api_key=api_key)
generation_config = {
"temperature": 0.5,
"top_p": 0.95,
"top_k": 64,
"max_output_tokens": 8192,
"response_mime_type": "text/plain",
}
The generation_config dictionary specifies parameters such as temperature, top-p, top-k, and max_output_tokens, which control the behavior of the text generation process.
Defining the System Prompt:
Here, we set up a system prompt to guide the AI's document extraction process. The prompt instructs the model to maintain the original structure and formatting of the PDF content using markdown syntax.
SYSTEM_PROMPT = """
You are a highly accurate document extraction model. Your task is to extract content from PDFs while maintaining the original structure and formatting using markdown syntax.When you encounter a plot or image, do not include any URLs or HTML tags. Instead, extract both the original title and description from the PDF, and generate a detailed description. Enclose all this information inside square brackets like this: `[Original title: Original description.] [Detailed description]`. Ensure the content is unaltered and free of unnecessary code.
"""
It also specifies how to handle plots or images by extracting and detailing titles and descriptions, all enclosed in square brackets without including URLs or HTML tags.
Initializing the Gemini Model:
We create an instance of the Gemini model using the genai.GenerativeModel class, providing it with the system prompt and generation configuration.
gemini_model = genai.GenerativeModel("models/gemini-1.5-flash",
system_instruction=SYSTEM_PROMPT,
generation_config=generation_config)
Defining the User Prompt:
The USER_PROMPT is set up to instruct the model on how to extract and format content from a PDF file. This prompt is nearly a repetition of the system prompt but is tailored for user-specific instructions. It directs the model to maintain the original document structure and format using markdown. The prompt also specifies how to handle plots and images by including both the original title and description from the PDF along with a generated detailed description, enclosed in square brackets.
USER_PROMPT = """
Extract the content from this PDF without changing anything. Preserve the original structure and use markdowns for formatting. When you find plots or images, include both the original title and description from the PDF along with a generated detailed description, all enclosed inside square brackets, like `[Original title: Original description.] [Detailed description]`. Do not include URLs or HTML tags.
"""
This repetition ensures that the model adheres to consistent formatting rules and extraction details throughout the
Uploading a File to Gemini:
The upload_to_gemini function uploads a specified file to Gemini.
def upload_to_gemini(path, mime_type=None):
"""
Uploads the given file to Gemini.
"""
file = genai.upload_file(path, mime_type=mime_type)
return file
It accepts a file path and an optional MIME type, then uses the genai.upload_file method to handle the file upload, returning the uploaded file object for further processing.
Converting PDF to Markdown:
The pdf2markdown function converts a PDF file to markdown format. It uploads the PDF to Gemini, then uses the gemini_model to generate content based on the user prompt.
def pdf2markdown(pdf_path):
files = [ upload_to_gemini(pdf_path, mime_type="application/pdf"),]
response = gemini_model.generate_content([files[0] , USER_PROMPT])
return response.text
The function returns the extracted markdown content, which preserves the original structure and formatting of the document.
markdown = pdf2markdown("/path/file.pdf")
Displaying the Extracted Markdown:
Finally, we display the extracted markdown content in a Jupyter Notebook using IPython’s display and Markdown functions.
from IPython.display import display, Markdown
display(Markdown(markdown))
This renders the markdown content so that it is visually formatted and easy to review within the notebook environment.
For better results in Retrieval-Augmented Generation (RAG) systems, high-quality input data is crucial. Tools such as LlamaParse, Marker-PDF, and the Nougat model offer advanced parsing to ensure that documents are well-structured and accurate. Multimodal Large Language Models (MLLMs) like Gemini Flash can enhance the speed of data extraction. Leveraging these methods will significantly improve how your RAG applications handle complex documents, leading to more reliable and effective outcomes.