Sure, here’s how you can structure these sections for your project guide:
Text Extraction and Structuring using Large Language Models
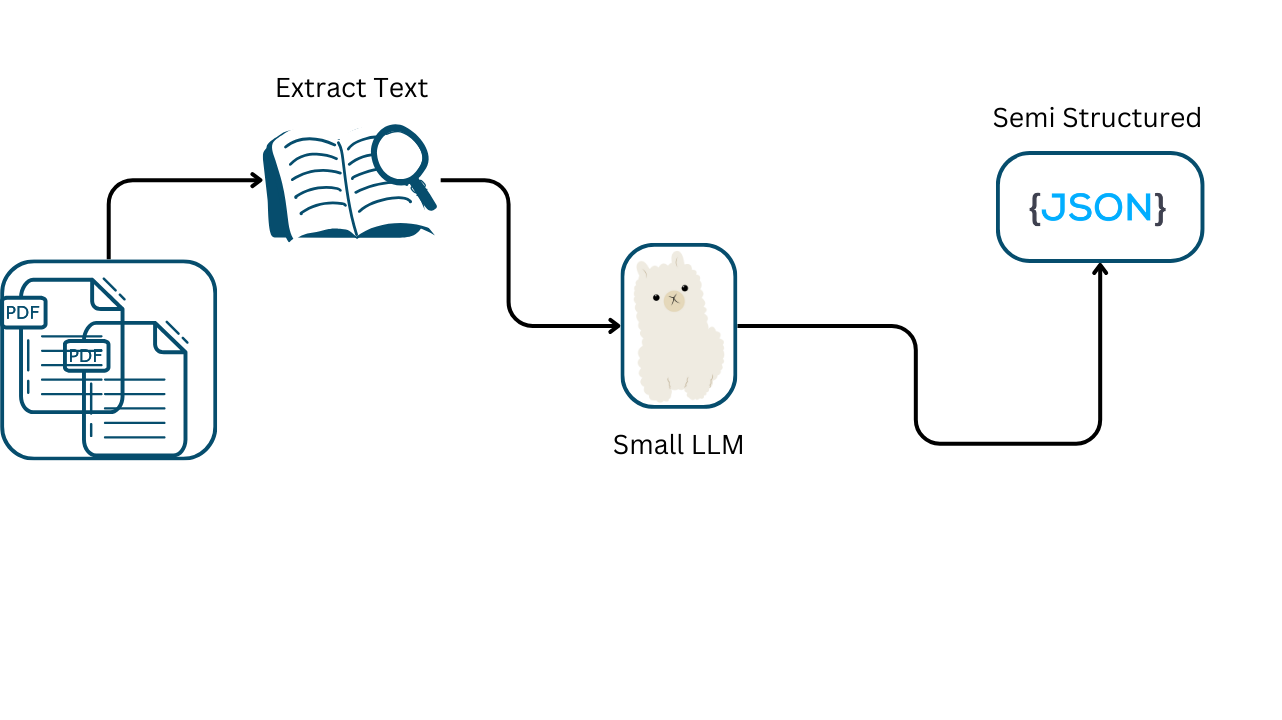
Data extraction and structuring are crucial tasks in processing large volumes of text, enabling efficient organization and retrieval of information. Leveraging advanced language models (LLMs) for these tasks can significantly enhance accuracy and automation. This guide explores how LLMs, particularly the Phi-3 model, can be utilized to streamline and improve data extraction and structuring processes.
Why Use LLMs for This
Large Language Models (LLMs) are ideal for data extraction and structuring due to their ability to understand and process vast amounts of text with high accuracy. They can automatically identify and categorize information, recognize patterns, and maintain context across lengthy documents. This capability reduces manual effort and increases efficiency, making LLMs a powerful tool for handling complex text processing tasks.
Why Choose the Phi-3 Model?
The Phi-3 model, especially the microsoft/Phi-3-mini-128k-instruct variant, is an excellent choice for text filtering, data extraction, and structuring due to its distinctive features:
Size and Efficiency: The Phi-3 model offers a compact yet powerful solution, balancing performance and resource usage effectively. This makes it well-suited for filtering tasks without imposing excessive computational demands
Large Context Window (128k Tokens): A notable advantage of Phi-3 is its large context window, which enables the model to handle up to 128k tokens in a single pass. This is crucial for processing lengthy documents and maintaining coherence, thereby enhancing the accuracy of data extraction and structuring
Contextual Understanding: Phi-3 excels in contextual comprehension, thanks to its advanced architecture and training. This deep understanding is essential for nuanced text filtering and extraction tasks, such as detecting sensitive information and categorizing content with complex criteria.
Code Example
Login to Hugging Face
This command logs you into your Hugging Face account via the command line. It uses the --token flag to provide your authentication token, allowing access to download and use models from Hugging Face’s hub.
Make sure to replace the token with your actual one to ensure proper access.
! huggingface-cli login --token XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Importing Libraries
We import the necessary libraries to perform our task.
from transformers import pipeline
from datasets import load_dataset
from tqdm import tqdm
import pandas as pd
import re
import json
import fitz
import os
Setup the text-generation pipeline
To use the pipeline function for text generation with the microsoft/Phi-3-mini-128k-instruct model, first, the code sets up a text-generation pipeline by specifying the task as text-generation. This tells the model that it will be used for generating text based on the input it receives. In the next step, it loads the microsoft/Phi-3-mini-128k-instruct model, which is designed to handle large context windows and is well-suited for generating detailed and coherent text.
pipe = pipeline("text-generation",
model="microsoft/Phi-3-mini-128k-instruct",
trust_remote_code=True)
The trust_remote_code=True argument is included to ensure that code from the model repository is trusted and executed, which is necessary for the model to function correctly.
Define the system prompt and user prompt
The system_prompt sets up the model to extract titles and text from PDFs exactly as they appear, while the user_prompt directs the model to process the parsed text, ensuring no modification and returning results in a clear JSON format with titles and their associated text.
system_prompt = """
You are a text extraction model specialized in extracting titles and their corresponding text from parsed PDF content. Ensure that the extracted content is preserved exactly as it appears in the PDF.
"""
user_prompt = """
Please process the provided parsed PDF text and extract titles and their corresponding text as they appear in the document. Do not rephrase or modify the content. Return the results in JSON format, where each entry includes the title and the associated text.
**Format:**
```json
[
{
"title": "Exact Title from PDF",
"text": "Exact text associated with the title from PDF"
},
{
"title": "Another Title",
"text": "Text associated with another title"
}
]
```
"""
Define the Geneation Function
In the text2json function, the process begins by creating a list of messages where the system_prompt and user_prompt define the model's role and task. It then includes the parsed PDF text with a label to direct the model.
def text2json(text) :
"""
This function takes a string as input and returns a JSON-formatted text structure with titles and their corresponding text.
"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
{"role": "user", "content": f"MY PDF : {text}" }
]
generation_args = {
"max_new_tokens": 4096,
"return_full_text": True,
"temperature": 0.0,
"do_sample": False
}
output = pipe(messages, **generation_args)
return output[0]['generated_text'][3]['content']
After setting up the message list, the function specifies the generation parameters, such as a maximum of 4096 tokens and a temperature of 0.0 for deterministic output. Next, it runs the pipe function with these messages and parameters to generate the output. Finally, the function returns the content from the generated text in JSON format.
Define Pdf parser function
The parse_pdf function starts by initializing an empty string to hold the combined text from the PDF. It then opens the specified PDF file and iterates through each page to extract text using fitz. For each page, the extracted text is appended to the combined_text string.
def parse_pdf(file_path):
"""
Parse the specified PDF file and extract its text into a single string.
Args:
file_path (str): The path to the PDF file.
Returns:
str: The text extracted from the PDF.
"""
combined_text = ""
try:
# Open the PDF file
pdf_document = fitz.open(file_path)
# Extract text from each page
for page_num in range(len(pdf_document)):
page = pdf_document.load_page(page_num)
combined_text += page.get_text()
pdf_document.close()
except Exception as e:
print(f"Error processing {file_path}: {e}")
return combined_text
After processing all pages, the function closes the PDF document and returns the combined text as a single string. If any error occurs during this process, it prints an error message.
Define Json Extraction Function
The extract_json_from_string function begins by initializing two lists: one for storing successfully extracted json objects and another for capturing errors.
It uses a regular expression to search for json-like structures within the provided text. If no matches are found, an error is recorded. For each JSON string identified, the function attempts to parse it into a json object using json.loads.
def extract_json_from_string(text):
"""
Extract json objects from a string.
Args:
text (str): The string to search for json objects.
Returns:
tuple: A tuple containing two lists: one for successfully extracted json objects, and another for errors.
"""
objs = []
errors = []
# Use regex to find JSON-like structures in the text
matches = re.findall(r'{.*}', text, re.DOTALL)
if not matches:
errors.append("No JSON patterns found")
for index, json_string in enumerate(matches):
try:
# Load JSON object
json_obj = json.loads(json_string)
objs.append(json_obj)
except json.JSONDecodeError as e:
errors.append((index, json_string, f"JSONDecodeError: {e}"))
except Exception as e:
errors.append((index, json_string, f"Error: {e}"))
return objs, errors
Successfully parsed objects are added to the objs list, while any parsing errors are recorded along with the index and the problematic string.
Finally, the function returns both the list of json objects and the list of errors encountered during extraction.
Define Main Function
The llm_extractor function starts by generating a list of pdf files in the specified folder path, filtering for files with a .pdf extension.
It then initializes an empty list to store results. For each pdf file, the function parses the text using parse_pdf, processes it with text2json to extract json data, and uses extract_json_from_string to parse the json.
def llm_extractor(folder_path) :
"""
Extract json objects from pdf files in the specified folder.
Args:
folder_path (str): The path to the folder containing the pdf files.
Returns:
DataFrame: A pandas DataFrame containing the extracted json objects.
"""
pdf_files = [os.path.join(folder_path, file) for file in os.listdir(folder_path) if file.lower().endswith('.pdf')]
obj_list = []
for i in pdf_files :
pdf_text = parse_pdf(i)
text_json = text2json(pdf_text)
objs, _ = extract_json_from_string(text_json)
obj_list.append({"pdf_file_name" : i , "text" :pdf_text , "json" : objs[0]})
final_df = pd.DataFrame(obj_list)
return final_df
The results, including the pdf file name, the extracted text, and the json object, are appended to the obj_list.
Finally, the function converts this list into a DataFrame and returns it.
Test the Function
To test the llm_extractor function, you can use the following code:
final_df = llm_extractor(folder_path="/kaggle/working/data")
You can save the result to a csv file using the following code:
final_df.to_csv("output.csv")